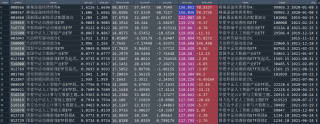
python爬虫
http://vip.stock.finance.sina.com.cn/fund_center/index.html#hbphall
抓取所有基金的信息
我先写了基金代码的一部分,但是运行后没有结果,想要问问是什么问题
import requests
from bs4 import BeautifulSoup
import time
import random
import re
import pandas as pd
import matplotlib.pyplot as plt
class Jijin:
def __init__(self):
self.URL = "http://vip.stock.finance.sina.com.cn/fund_center/index.html#hbphall"
self.startnum = [i for i in range(0, 11652, 40)]
self.header = {
'User-Agent': 'Mozilla/5.0 (Macintosh; Intel Mac OS X 10_15_7) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/110.0.0.0 Safari/537.36'}
def getinf(self):
self.num = []
# self.name = []
# self.unitvalue = []
# self.totalvalue = []
# self.performance1 = []
# self.performance2 = []
# self.performance3 = []
# self.performance4 = []
# self.performance5 = []
for start in self.startnum:
time.sleep(random.randint(1, 5)) # 伪装成人为随机时间点击
html = requests.get(self.URL, params={"start": str(start)}, headers=self.header)
soup = BeautifulSoup(html.text, "html.parser")
nums = soup.select(
'#divHBPH.p_r > div.relative_outer > div#cHBPH.fundTab.table.fblue > table > tbody > tr.red > td.colorize > a')
# names =
# unitvalues =
# totalvalues =
# performance1s =
# performance2s =
# performance3s =
# performance4s =
# performance5s =
for numi in nums:
self.num.append(numi.text)
print(self.num)
self.result = pd.DataFrame(zip(self.num))
# 没有返回结果
def print_result(self):
# print('*'*60)
pd.set_option('display.max_rows', None) # 显示pandas所有行
return self.result
# 返回一个结果
pass
if __name__ == '__main__':
cls = Jijin()
cls.getinf()
cls.print_result()