
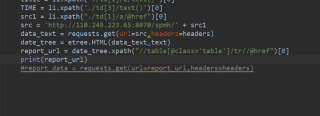

已经爬取了每个PDF文件的下载直链,但直链包含中文怎么解决?

已经爬取了每个PDF文件的下载直链,但直链包含中文怎么解决?
 分享
分享
处理title,time把无关的字符去掉 title.strip(),time.strip()
分享 系统已结题
3月9日
系统已结题
3月9日 已采纳回答
3月1日
修改了问题
2月28日
修改了问题
2月28日
已采纳回答
3月1日
修改了问题
2月28日
修改了问题
2月28日


