from bs4 import BeautifulSoup # 网页分析,获取数据
import re # 正则表达式,进行文字匹配
import urllib.request, urllib.error # 制定URL,获取网页数据
import xlwt # 进行excel操作
import sqlite3 # 进行SQLite数据库操作
def main():
baseurl = "https://movie.douban.com/top250?start="
# 1.爬取网页
datalist = getData(baseurl)
# 2.解析数据
savepath = ".\\豆瓣电影top250.xls" # 保存路径
# 3.保存数据
# saveData(savepath)
# askURL("https://movie.douban.com/top250?start=")
# 影片详情链接的规则
findLink = re.compile(r'') # 创建正则表达式对象,表示规则(字符串的模式)r:忽略特殊符号,如/,//
# 影片图片规则
findImgSrc = re.compile(r'<img.*src="(.*?)"', re.S)
# 影片片名
findTitle = re.compile(r'(.*?)')
# 影片评分
findRating = re.compile(r'(.*)')
# 评价人数
findJudge = re.compile(r'(/d*)人评价')
# 概况
findInq = re.compile(r'(.*)')
# 影片相关内容
findBD = re.compile(r'(.*?)
', re.S)
# 1.爬取网页
def getData(baseurl):
datalist = []
for i in range(0, 10): # 调用获取页面信息的函数,10次
url = baseurl + str(i * 25)
html = askURL(url) # 保存获取的网页源码
# 2.逐一解析数据
soup = BeautifulSoup(html, 'html.parser')
for item in soup.find_all('div', class_="item"):
# print(item)
data = [] # 保存一部电影的所有信息
item = str(item)
# 获取影片详情链接
link = re.findall(findLink, item)[0]
data.append(link)
# print(link) #测试
ImgSrc = re.findall(findImgSrc, item)[0]
data.append(ImgSrc)
Titles = re.findall(findTitle, item)
if (len(Titles) == 2):
ctitle = Titles[0]
data.append(ctitle)
otitle = Titles[1].replace('/', '')
data.append(otitle)@@
else:
data.append(Titles[0])
data.append(' ')
rating = re.findall(findRating, item)[0]
data.append(rating)
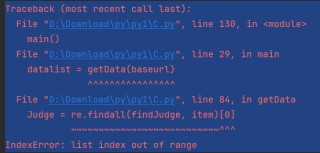
** Judge = re.findall(findJudge, item)[0]**
data.append(Judge)
inq = re.findall(findInq, item)
data.append(inq)
if len(inq) != 0:
inq = inq[0].replace('。', '')
data.append(inq)
else:
data.append(' ')
BD = re.findall(findBD, item)[0]
BD = re.sub('<br(\s+)?/>(\s+)?', " ", BD)
BD = re.sub('/', ' ', BD)
data.append(BD.strip())
错误: