自学Python爬虫,遇到识别验证码,使用云码不知道具体怎么操作,请大家指点。
云码网址:
https://zhuce.jfbym.com/own/index/index
我操作图片如下:请指点,写出具体的代码,谢谢!
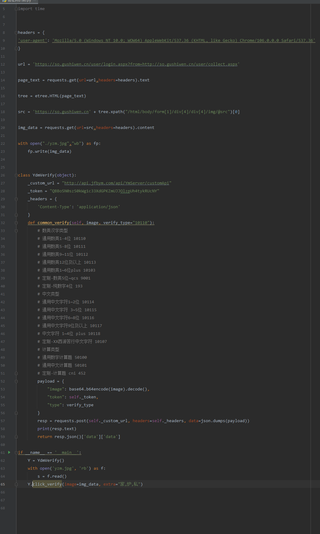

自学Python爬虫,遇到识别验证码,使用云码不知道具体怎么操作,请大家指点。
云码网址:
https://zhuce.jfbym.com/own/index/index
我操作图片如下:请指点,写出具体的代码,谢谢!
 分享
分享参考GPT和自己的思路,根据您的代码,您需要调用云码的API接口来识别验证码。云码提供了基于HTTP POST的API接口,您可以将验证码图片文件作为二进制数据上传到API服务器,并获取识别结果。
以下是一个简单的示例代码,您可以在代码中填写您的API Token和验证码图片文件路径,然后运行程序即可实现验证码识别。
import base64
import json
import requests
class YunMaVerify(object):
def __init__(self, token):
self._token = token
self._api_url = "http://api.jfbym.com/api/YmServer/customApi"
def verify(self, image_path, verify_type):
with open(image_path, 'rb') as f:
image_data = f.read()
image_base64 = base64.b64encode(image_data).decode('utf-8')
payload = {
'image': image_base64,
'token': self._token,
'type': verify_type
}
headers = {
'Content-Type': 'application/json'
}
response = requests.post(self._api_url, headers=headers, data=json.dumps(payload))
response_data = json.loads(response.text)
if response_data['success']:
return response_data['data']
else:
raise Exception('Failed to verify captcha: %s' % response_data['msg'])
if __name__ == '__main__':
token = 'YOUR_API_TOKEN_HERE'
image_path = '/path/to/your/captcha/image.jpg'
verify_type = '10111' # 通用数英5-8位
yunma = YunMaVerify(token)
result = yunma.verify(image_path, verify_type)
print(result)
请注意,此示例代码仅用于演示云码API的基本使用方法。您需要将代码中的YOUR_API_TOKEN_HERE替换为您自己的API Token,并将/path/to/your/captcha/image.jpg替换为您的验证码图片文件路径。另外,请根据您的验证码类型选择合适的verify_type参数。如果您的验证码类型不是通用数英5-8位,请将verify_type参数替换为您自己的类型。
希望这可以帮助您解决问题。如果您有任何其他问题,请随时问我。
分享 系统已结题
3月12日
系统已结题
3月12日 已采纳回答
3月4日
创建了问题
3月4日
已采纳回答
3月4日
创建了问题
3月4日

