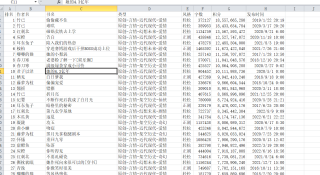
使用Python爬虫,代码没有问题,我是用的pycharm,朋友用的Vscode,她可以运行但是我运行不了,结果返回是空的,也不报错,以下是代码
import requests
import re
import pandas as pd
from lxml import etree
from bs4 import BeautifulSoup
import pandas as pd
import matplotlib.pyplot as plt
url = 'https://www.jjwxc.net/topten.php?orderstr=7&t=0'
headers = {
'cookie': '__yjs_duid=1_695ffee74a69dc5584c310ec8801cdd11673344566448; testcookie=yes; '
'Hm_lvt_bc3b748c21fe5cf393d26c12b2c38d99=1673344567; timeOffset_o=-1159.10009765625; '
'smidV2=202301101756406f750a4c79547b98806fb79f3c774d7a00acd69b212a2e0b0; '
'JJEVER={"fenzhan":"yq","isKindle":"","background":"","font_size":""}; '
'JJSESS={"referer":"/book2/7322952"}; '
'Hm_lpvt_bc3b748c21fe5cf393d26c12b2c38d99=1673358311',
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) '
'AppleWebKit/537.36 (KHTML, like Gecko) Chrome/108.0.0.0 Safari/537.36'
}
response = requests.get(url=url, headers=headers)
text = response.content.decode('gbk') # 获取网页源码,以文本形式显示
soup = BeautifulSoup(text, 'lxml')
def get_data_all(td):
# 排名
pm = td[0].text
# 作者名
zz = td[1].text.replace('\xa0', '').replace('\n', '')
# 书名
sm = td[2].text.replace('\n', '').replace('\xa0', '')
# 类型
lx = td[3].text.replace('\n', '').replace('\xa0', '').replace('\r', '').replace(' ', '')
# 风格
fg = td[4].text
# 字数
zs = td[6].text.replace('\n', '').replace('\xa0', '')
# 积分
jf = td[7].text.replace('\n', '').replace('\xa0', '').replace('\r', '')
# 发布时间
fbsj = td[8].text
return [pm, zz, sm, lx, fg, zs, jf, fbsj]
def get_data(url):
headers = {
'cookie': '__yjs_duid=1_695ffee74a69dc5584c310ec8801cdd11673344566448; testcookie=yes; '
'Hm_lvt_bc3b748c21fe5cf393d26c12b2c38d99=1673344567; timeOffset_o=-1159.10009765625; '
'smidV2=202301101756406f750a4c79547b98806fb79f3c774d7a00acd69b212a2e0b0; '
'JJEVER={"fenzhan":"yq","isKindle":"","background":"","font_size":""}; '
'JJSESS={"referer":"/book2/7322952"}; Hm_lpvt_bc3b748c21fe5cf393d26c12b2c38d99=1673358311',
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) '
'AppleWebKit/537.36 (KHTML, like Gecko) Chrome/108.0.0.0 Safari/537.36'
}
response = requests.get(url=url, headers=headers)
text = response.content.decode('gbk') # 获取网页源码,以文本形式显
# 构造bs对象
soup = BeautifulSoup(text, 'lxml')
# 查找详细信息所在的tr节点
tr = soup.find_all('tr', attrs={'bgcolor': '#eefaee'})
list_all = []
# 循环查找到的tr节点,并把获取到的信息依次存进空列表list_all
for i in range(len(tr)):
td = tr[i].find_all('td')
add = get_data_all(td) # 获取信息信息
list_all.append(add) # 存进列表
# 存进小表格
df = pd.DataFrame(list_all, columns=['排名', '作者名', '书名', '类型', '风格', '字数', '积分', '发布时间'])
return df
df_all = get_data(url=url)
# 导出数据
df_all.to_csv(r'data.csv', index=False, encoding='utf_8_sig')
有人提议这可能是库的版本问题,附图
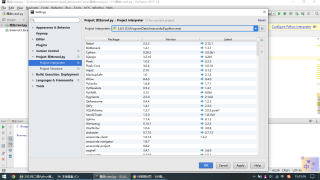
请问如何解决呢