



请问怎么能用pandas筛选csv文件里一列包含字典key值的行,并根据字典value值分类
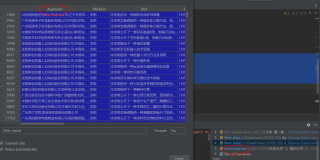
用这个学校字典匹配applicant里含有学校的行,并且根据字典的值分类储存

请问怎么能用pandas筛选csv文件里一列包含字典key值的行,并根据字典value值分类
用这个学校字典匹配applicant里含有学校的行,并且根据字典的值分类储存
 分享
分享 系统已结题
3月17日
系统已结题
3月17日 已采纳回答
3月10日
赞助了问题酬金15元
3月10日
修改了问题
3月10日
已采纳回答
3月10日
赞助了问题酬金15元
3月10日
修改了问题
3月10日












