
在用SQL获取数据库信息进行计算处理时,发现同一日期(天)内同一ID存在相同的记录(行),需要去掉同一日期内同一ID的相同行,仅保留其中一行即可,根据日期以此类推,最终提取一段时间内每天无同一ID重复的数据记录,怎么用SQL语句表现?如图说明。谢谢!
图1

图2
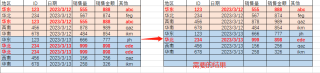

在用SQL获取数据库信息进行计算处理时,发现同一日期(天)内同一ID存在相同的记录(行),需要去掉同一日期内同一ID的相同行,仅保留其中一行即可,根据日期以此类推,最终提取一段时间内每天无同一ID重复的数据记录,怎么用SQL语句表现?如图说明。谢谢!
图1
 分享
分享
可以使用窗口函数和子查询来实现。
假设表格名为table_name,日期列为date_column,ID列为id_column,其他需要保留的列为column1和column2,需要提取的时间段为从start_date到end_date。
基本思路如下:
SQL语句如下:
SELECT date_column, id_column, column1, column2
FROM (
SELECT date_column, id_column, column1, column2,
ROW_NUMBER() OVER (PARTITION BY date_column, id_column ORDER BY date_column) AS row_num
FROM table_name
WHERE date_column BETWEEN start_date AND end_date
) subquery
WHERE row_num = 1
 系统已结题
3月20日
系统已结题
3月20日 已采纳回答
3月12日
创建了问题
3月11日
已采纳回答
3月12日
创建了问题
3月11日

