
#Spark 启动时报错
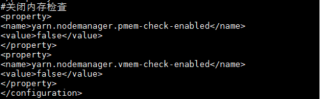
在hoodoop集群成功开启,Hadoop的Yarn配置文件yarn-site.xml,增加关闭内存检查配置,防火墙已关闭的前提下,使用命令spark-submit --master yarn-client --class org.apache.spark.examples.SparkPi /usr/spark/examples/jars/spark-examples_2.11-2.0.1.jar 100,调用SparkPi时,出现报错,拒接连接
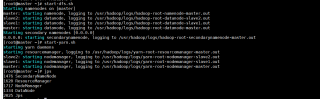
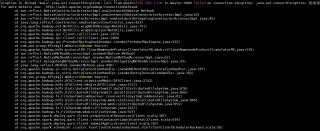
Exception in thread "main" java.net.ConnectException: Call From master/192.168.3.190 to master:9000 failed on connection exception: java.net.ConnectException: 拒绝连接; For more details see: http://wiki.apache.org/hadoop/ConnectionRefused
at sun.reflect.NativeConstructorAccessorImpl.newInstance0(Native Method)
at sun.reflect.NativeConstructorAccessorImpl.newInstance(NativeConstructorAccessorImpl.java:62)
at sun.reflect.DelegatingConstructorAccessorImpl.newInstance(DelegatingConstructorAccessorImpl.java:45)
at java.lang.reflect.Constructor.newInstance(Constructor.java:423)
at org.apache.hadoop.net.NetUtils.wrapWithMessage(NetUtils.java:791)
at org.apache.hadoop.net.NetUtils.wrapException(NetUtils.java:731)
at org.apache.hadoop.ipc.Client.call(Client.java:1473)
at org.apache.hadoop.ipc.Client.call(Client.java:1400)
at org.apache.hadoop.ipc.ProtobufRpcEngine$Invoker.invoke(ProtobufRpcEngine.java:232)
at com.sun.proxy.$Proxy11.mkdirs(Unknown Source)
at org.apache.hadoop.hdfs.protocolPB.ClientNamenodeProtocolTranslatorPB.mkdirs(ClientNamenodeProtocolTranslatorPB.java:539)
at sun.reflect.NativeMethodAccessorImpl.invoke0(Native Method)
at sun.reflect.NativeMethodAccessorImpl.invoke(NativeMethodAccessorImpl.java:62)
at sun.reflect.DelegatingMethodAccessorImpl.invoke(DelegatingMethodAccessorImpl.java:43)
at java.lang.reflect.Method.invoke(Method.java:498)
at org.apache.hadoop.io.retry.RetryInvocationHandler.invokeMethod(RetryInvocationHandler.java:187)
at org.apache.hadoop.io.retry.RetryInvocationHandler.invoke(RetryInvocationHandler.java:102)
at com.sun.proxy.$Proxy12.mkdirs(Unknown Source)
at org.apache.hadoop.hdfs.DFSClient.primitiveMkdir(DFSClient.java:2742)
at org.apache.hadoop.hdfs.DFSClient.mkdirs(DFSClient.java:2713)
at org.apache.hadoop.hdfs.DistributedFileSystem$17.doCall(DistributedFileSystem.java:870)
at org.apache.hadoop.hdfs.DistributedFileSystem$17.doCall(DistributedFileSystem.java:866)
at org.apache.hadoop.fs.FileSystemLinkResolver.resolve(FileSystemLinkResolver.java:81)
at org.apache.hadoop.hdfs.DistributedFileSystem.mkdirsInternal(DistributedFileSystem.java:866)
at org.apache.hadoop.hdfs.DistributedFileSystem.mkdirs(DistributedFileSystem.java:859)
at org.apache.hadoop.fs.FileSystem.mkdirs(FileSystem.java:1817)
at org.apache.hadoop.fs.FileSystem.mkdirs(FileSystem.java:597)
at org.apache.spark.deploy.yarn.Client.prepareLocalResources(Client.scala:385)
at org.apache.spark.deploy.yarn.Client.createContainerLaunchContext(Client.scala:834)
at org.apache.spark.deploy.yarn.Client.submitApplication(Client.scala:167)
at org.apache.spark.scheduler.cluster.YarnClientSchedulerBackend.start(YarnClientSchedulerBackend.scala:56)
at org.apache.spark.scheduler.TaskSchedulerImpl.start(TaskSchedulerImpl.scala:149)
at org.apache.spark.SparkContext.<init>(SparkContext.scala:497)
at org.apache.spark.SparkContext$.getOrCreate(SparkContext.scala:2275)
at org.apache.spark.sql.SparkSession$Builder$$anonfun$8.apply(SparkSession.scala:831)
at org.apache.spark.sql.SparkSession$Builder$$anonfun$8.apply(SparkSession.scala:823)
at scala.Option.getOrElse(Option.scala:121)
at org.apache.spark.sql.SparkSession$Builder.getOrCreate(SparkSession.scala:823)
at org.apache.spark.examples.SparkPi$.main(SparkPi.scala:31)
at org.apache.spark.examples.SparkPi.main(SparkPi.scala)
at sun.reflect.NativeMethodAccessorImpl.invoke0(Native Method)
at sun.reflect.NativeMethodAccessorImpl.invoke(NativeMethodAccessorImpl.java:62)
at sun.reflect.DelegatingMethodAccessorImpl.invoke(DelegatingMethodAccessorImpl.java:43)
at java.lang.reflect.Method.invoke(Method.java:498)
at org.apache.spark.deploy.SparkSubmit$.org$apache$spark$deploy$SparkSubmit$$runMain(SparkSubmit.scala:736)
at org.apache.spark.deploy.SparkSubmit$.doRunMain$1(SparkSubmit.scala:185)
at org.apache.spark.deploy.SparkSubmit$.submit(SparkSubmit.scala:210)
at org.apache.spark.deploy.SparkSubmit$.main(SparkSubmit.scala:124)
at org.apache.spark.deploy.SparkSubmit.main(SparkSubmit.scala)
Caused by: java.net.ConnectException: 拒绝连接
at sun.nio.ch.SocketChannelImpl.checkConnect(Native Method)
at sun.nio.ch.SocketChannelImpl.finishConnect(SocketChannelImpl.java:715)
at org.apache.hadoop.net.SocketIOWithTimeout.connect(SocketIOWithTimeout.java:206)
at org.apache.hadoop.net.NetUtils.connect(NetUtils.java:530)
at org.apache.hadoop.net.NetUtils.connect(NetUtils.java:494)
at org.apache.hadoop.ipc.Client$Connection.setupConnection(Client.java:608)
at org.apache.hadoop.ipc.Client$Connection.setupIOstreams(Client.java:706)
at org.apache.hadoop.ipc.Client$Connection.access$2800(Client.java:369)
at org.apache.hadoop.ipc.Client.getConnection(Client.java:1522)
at org.apache.hadoop.ipc.Client.call(Client.java:1439)
... 42 more







