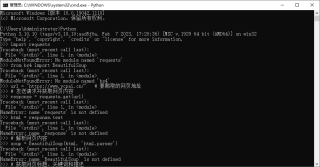
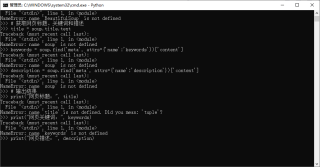
请问下面这段Python代码有什么问题?
import requests
from bs4 import BeautifulSoup
url = "https://www.ycpai.cn/" # 要爬取的网页地址
# 发送请求并获取网页内容
response = requests.get(url)
html = response.text
# 解析网页内容
soup = BeautifulSoup(html, 'html.parser')
# 获取网页标题、关键词和描述
title = soup.title.text
keywords = soup.find('meta', attrs={'name':'keywords'})['content']
description = soup.find('meta', attrs={'name':'description'})['content']
# 输出结果
print("网页标题:", title)
print("网页关键词:", keywords)
print("网页描述:", description)
使用命令行工具执行结果如下图