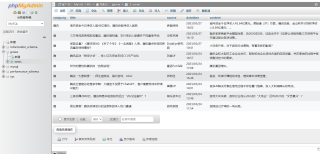
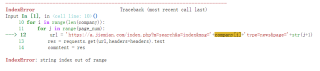
把爬取的数据放进mysql时提示“string index out of range,而且数据库里的公司名不全的状况
以下是代码
import requests
import re
import time
import numpy
import pymysql
import pandas
headers= {'User-Agent':'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/95.0.4638.54 Safari/537.36'}
company = ["腾讯","百度"]
page_num= 1
for i in range(len(company)):
for j in range(page_num):
url = 'https://a.jiemian.com/index.php?m=search&a=index&msg='+company[i]+'type=news&page='+str(j+1)
res = requests.get(url,headers=headers).text
comntent = res
p_allnews = '<div class="news-view left">(.*?)</div></div></div>'
result_all = re.findall(p_allnews,comntent,re.S)
new_single=[]
for l in range(len(result_all)):
p_title = '<div class="news-header"><h3><a href=.*?target="_blank" title="(.*?)">'
title = re.findall(p_title,result_all[l])
if title ==[]:
title.append("没有标题")
p_s = '<span class="author"><a href=.*? target="_blank">(.*?)</a> '
s = re.findall(p_s,result_all[l].strip(),re.S)
if s ==[]:
s.append("没有来源")
p_dt = '<span class="date">(.*?)</span>'
dt = re.findall(p_dt,result_all[l].strip(),re.S)
if dt ==[]:
dt.append("没有时间")
p_c = '<div class="news-main"><p>(.*?)</p></div>'
c = re.findall(p_c,result_all[l].strip(),re.S)
if c ==[]:
c.append("没有内容")
print(str(l+1)+'.'+title[0])
print("来源:"+s[0]+"\n发布日期:"+dt[0])
print("新闻摘要:"+c[0])
company = company[i]
title = title[0]
s = s[0]
dt = dt[0]
c = c[0]
db = pymysql.connect(host='localhost',port=3306,user='root',password='',database='jpnew',charset='utf8')
cur = db.cursor()
sql = "INSERT INTO `news` (`company`, `title`, `source`, `datatime`, `content`) VALUES (%s,%s,%s,%s,%s)"
cur.execute(sql,(company,title,s,dt,c))
db.commit()
cur.close()
db.close()
提示错误:string index out of range,而且数据库里的公司名不全的状况,为什么会出现这种情况,要怎么解决呢?
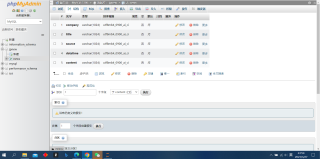
以下是数据库图片