
下载好了mysql的驱动jar包,但是在连接mysql的时候出现错误pyspark does not support any appliance options
请问这是什么原因

 分享
分享
 关注
关注1.启动pyspark,附加如下参数。
因为启动pyspark时,必须指定mysql连接驱动jar包(如果你前面已经采用下面方式启动了pyspark,就不需要重复启动了)。\表示换行。因为之前设置了SPARK_PATH环境变量,可以在全局输入pyspark启动,不需要进入bin目录。
pyspark \
--jars /usr/local/spark/jars/mysql-connector-java-8.0.26/mysql-connector-java-8.0.26.jar \
--driver-class-path /usr/local/spark/jars/mysql-connector-java-8.0.26/mysql-connector-java-8.0.26.jar
过程:

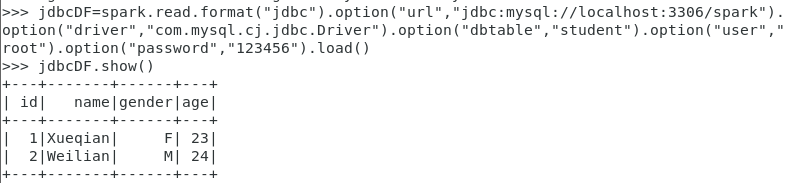
2.通过spark.read.format(“jdbc”).option().option()…操作通过JDBC连接MySql数据库时。
jdbcDF = spark.read.format("jdbc").option("url", "jdbc:mysql://localhost:3306/spark").option("driver","com.mysql.cj.jdbc.Driver").option("dbtable", "student").option("user", "root").option("password", "123456").load()
jdbcDF.show()
结果如图:
在pyspark中执行如下命令对数据进行读写:
from pyspark.sql.types import Row
from pyspark.sql.types import StructType
from pyspark.sql.types import StructField
from pyspark.sql.types import StringType
from pyspark.sql.types import IntegerType
studentRDD = spark.sparkContext.parallelize(["3 Rongcheng M 26","4 Guanhua M 27"]).map(lambda line : line.split(" "))
//下面要设置模式信息
schema = StructType([StructField("name", StringType(), True),StructField("gender", StringType(), True),StructField("age",IntegerType(), True)])
rowRDD = studentRDD.map(lambda p : Row(p[1].strip(), p[2].strip(),int(p[3])))
//建立起Row对象和模式之间的对应关系,也就是把数据和模式对应起来
studentDF = spark.createDataFrame(rowRDD, schema)
prop = {}
prop['user'] = 'root'
prop['password'] = '123456'
prop['driver'] = "com.mysql.cj.jdbc.Driver"
studentDF.write.jdbc("jdbc:mysql://localhost:3306/spark",'student','append', prop)
其中参数:
| 参数名称 | 含义 |
|---|---|
| url | 数据库的连接地址,如:jdbc:mysql://localhost:3306/spark(最后为数据库名) |
| Driver | 数据库的驱动程序,如:com.mysql.cj.jdbc.Driver |
| dbtable | 需要访问的表名 |
| user | 数据库用户名 |
| password | 数据库用户密码 |
过程:

在mysql中查看:

四、参考
1、驱动包下载和安装
分享 创建了问题
4月2日
创建了问题
4月2日



