
在控制台打的是这个命令
地址是: https://www.autohome.com.cn/b/

但是当我打开爬虫文件,看到里面的
start_urls = ["http://www.autohome.com.cn/"]
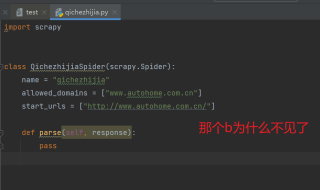
只能爬网站的主页吗?

在控制台打的是这个命令
地址是: https://www.autohome.com.cn/b/
但是当我打开爬虫文件,看到里面的
start_urls = ["http://www.autohome.com.cn/"]
 分享
分享
是这样的,没问题。scrapy认为加了/b/的不是一个正确的网站,因为一般的网站首页都是.com .cn这样结尾的。所以默认去掉了后面的。需要自己手动修改的。
分享 系统已结题
4月28日
系统已结题
4月28日 已采纳回答
4月20日
修改了问题
4月19日
创建了问题
4月19日
已采纳回答
4月20日
修改了问题
4月19日
创建了问题
4月19日


