
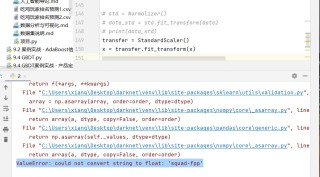
就是我数据集里面有几列是str类型的,然后我对数据集进行标准化就会报错
怎么解决这个问题

 分享
分享
 关注
关注标准化需要将数据转换成数值型数据,因此包含字符串类型的列会导致该错误。解决方法是将这些列进行编码或者删除这些列。如果这些列包含重要信息,则可以考虑使用一种编码方式,例如独热编码(One-Hot Encoding)来将其转换为数值型数据。在 Python 中,你可以使用 pandas 库中的 get_dummies() 函数实现独热编码。具体的参考代码如下:
import pandas as pd
# 假设你的 DataFrame 名称为 df,其中包含了要编码的列名为 'column_name'
encoded_df = pd.get_dummies(df['column_name'], prefix='col')
df = pd.concat([df, encoded_df], axis=1)
df.drop('column_name', axis=1, inplace=True) # 删除原始的列
执行这段代码后,你得到的就是一个新的 DataFrame,其中原来的字符串列已经被替换为数值型的列。
除了使用独热编码之外,还有一种方法是使用 LabelEncoder 对字符串类型的列进行编码。LabelEncoder 可以将字符串转换为整数,从而解决标准化时出现的 ValueError 错误。具体的参考代码如下:
from sklearn.preprocessing import LabelEncoder
# 假设你的 DataFrame 名称为 df,其中包含了要编码的列名为 'column_name'
le = LabelEncoder()
df['column_name'] = le.fit_transform(df['column_name'])
执行这段代码后,你得到的就是一个新的 DataFrame,其中原来的字符串列已经被替换为整数型的列。然后你就可以对该 DataFrame 进行标准化或其他的操作了。需要注意的是,LabelEncoder 编码的结果并不是唯一的,因此如果你的数据集中字符串的取值范围很大,可能会导致编码后的整数值过于密集,进而影响模型的效果。
分享 系统已结题
7月13日
系统已结题
7月13日 已采纳回答
7月5日
创建了问题
6月3日
已采纳回答
7月5日
创建了问题
6月3日


