想爬这个页面https://www. shanghairanking.cn/institution ,F12抓包后发现是访问api异步加载的,但是直接访问api/v2010/inst 的返回码是401,已经把cookie、authorization那些参数都复制了,但是还是不能访问成功,有懂的吗?
网上也没查到解决方法,都是爬排名的教程,没看到爬这个页面的
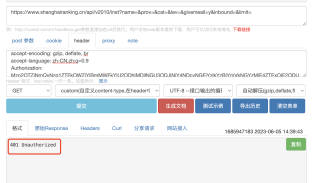

想爬这个页面https://www. shanghairanking.cn/institution ,F12抓包后发现是访问api异步加载的,但是直接访问api/v2010/inst 的返回码是401,已经把cookie、authorization那些参数都复制了,但是还是不能访问成功,有懂的吗?
网上也没查到解决方法,都是爬排名的教程,没看到爬这个页面的
 分享
分享
401错误说明访问被拒绝,可能是因为缺少某些必要的参数或者登录状态失效。我建议你尝试以下几个步骤:
分享 修改了问题
6月5日
修改了问题
6月5日
修改了问题
6月5日
创建了问题
6月5日
修改了问题
6月5日
修改了问题
6月5日
修改了问题
6月5日
创建了问题
6月5日


