n bind'", "/usr/share/logstash/vendor/bundle/jruby/2.3.0/gems/logstash-input-udp-3.1.3/lib/logstash/inputs/udp.rb:82:in udp_listener'", "/usr/share/logstash/vendor/bundle/jruby/2.3.0/gems/logstash-input-udp-3.1.3/lib/logstash/inputs/udp.rb:56:in run'", "/usr/share/logstash/logstash-core/lib/logstash/pipeline.rb:524:in inputworker'", "/usr/share/logstash/logstash-core/lib/logstash/pipeline.rb:517:in `bloc

关于#elk#的问题,请各位专家解答!(操作系统-linux)

- 写回答
- 好问题 0 提建议
- 关注问题
 分享
分享- 邀请回答
-

2条回答 默认 最新

 关注
关注- 这篇博客: 【Linux运维架构】------ 搭建 ELK 日志分析系统中的 第四步:创建索引 部分也许能够解决你的问题, 你可以仔细阅读以下内容或跳转源博客中阅读:
可以直接新建索引:
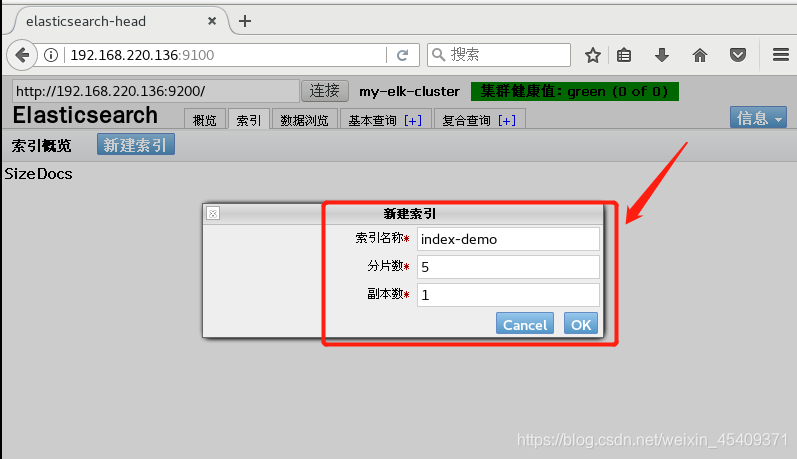
也可以输入以下命令创建索引:curl -XPUT '192.168.220.136:9200/index-demo/test/1?pretty&pretty' -H 'content-Type: application/json' -d '{"user":"zhangsan","mesg":"hello world"}' //索引名为 index-demo,类型为test
浏览器刷新一下,就会看到刚刚创建的索引信息,可以看出索引默认被分片5个,并且有一个副本。
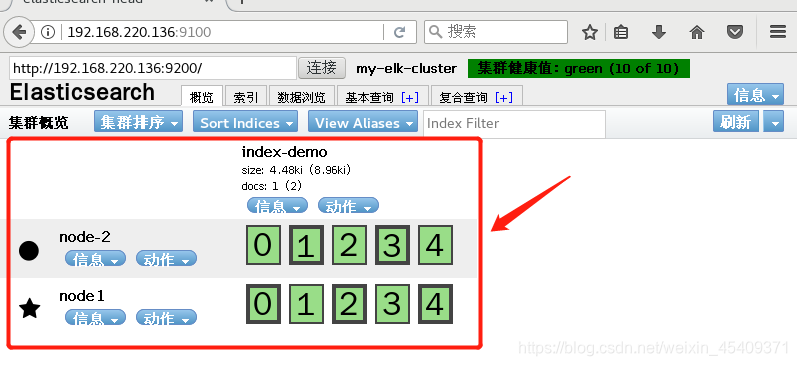
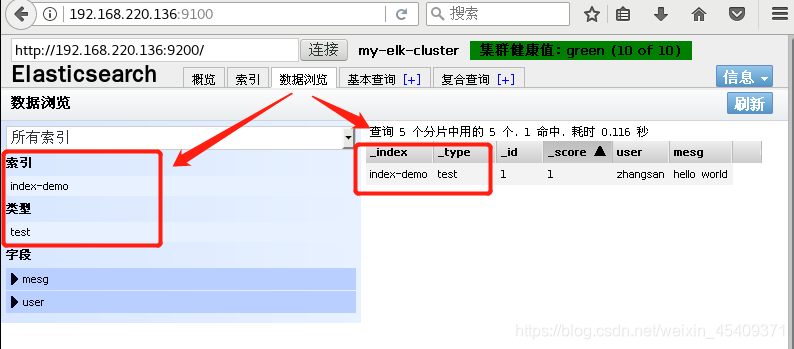
- 以下回答由chatgpt基于相关博客总结生成:
ELK是一个流行的日志管理工具,它由Elasticsearch、Logstash和Kibana三个不同但密切相关的组件组成。在Linux操作系统中,可以通过以下步骤使用ELK:
1.安装Elasticsearch、Logstash和Kibana组件,可以按照官方网站提供的安装教程进行操作。
2.在Logstash中配置input和output插件来读取和写入日志数据。例如,可以使用file input插件来读取一个日志文件,使用elasticsearch output插件将数据写入Elasticsearch集群中。
3.在Kibana中配置index pattern来指定要搜索的索引。这可以是一个通配符模式,例如“logstash-*”来匹配所有以logstash-开头的索引。
4.使用Kibana的搜索和过滤功能来查找特定的日志信息。可以通过在搜索栏中输入关键词或查询语句来进行搜索,并使用过滤器来限制搜索结果的范围。
以下是一个简单的Logstash配置文件示例,用于读取一个日志文件并将数据写入Elasticsearch集群中:
```input { file { path => "/var/log/messages" } }
output { elasticsearch { hosts => ["localhost:9200"] index => "logstash-%{+YYYY.MM.dd}" } }```
这个配置文件中,file input插件会读取/var/log/messages文件中的日志数据,并将其发送到output中。elasticsearch output插件将数据写入Elasticsearch集群中,使用logstash-yyyy.mm.dd的格式作为索引名称,其中yyyy.mm.dd表示当前日期。
关于如何搜索和过滤特定的日志信息,可以在Kibana中使用Query DSL语言编写查询表达式。例如,下面这个查询表达式可以查找包含关键词“error”的日志条目:
message:"error"如果要根据特定字段或范围来过滤搜索结果,可以使用filter子句。例如,下面这个查询表达式可以查找时间戳在特定日期之后的日志条目:
@timestamp: [2019-07-01T00:00:00Z TO *]更多关于查询语句和过滤器的信息可以参考Kibana官方文档。
解决 无用评论 打赏举报 分享- 这篇博客: 【Linux运维架构】------ 搭建 ELK 日志分析系统中的 第四步:创建索引 部分也许能够解决你的问题, 你可以仔细阅读以下内容或跳转源博客中阅读:
- 2022-11-02 00:51"Linux运维-04-日志分析-日志监控ELK-day03-生产案例及Git版本控制"这个主题深入探讨了如何使用ELK(Elasticsearch、Logstash、Kibana)堆栈进行日志管理和分析,并结合Git进行版本控制,以提升工作效率。...
- 2022-06-01 18:38此外,压缩包中的资料可能还会涵盖系统监控工具(如Nagios、Zabbix)、日志管理(如Logstash、ELK Stack)、性能分析(如top、iostat)等相关内容,这些都是Linux运维中的重要工具,对于理解并优化云计算集群的运行...
- 2021-12-24 20:32王少鱼456的博客 •elasticsearch应用场景: • 信息检索 • 日志分析 • 业务数据分析 • 数据库加速 • 运维指标监控 一、Elasticsearch分布式部署 操作:在test1,test2,test3中 (1)软件下载 软件下载地址:下载中心 - Elastic ...
- 2025-02-13 10:06秀儿*的博客 在回答这个问题时,要简洁地概括自己的工作背景,突出自己与系统运维相关的经历。例如,可以提到自己在某公司负责的主要工作,包括操作系统管理、服务器维护、自动化运维等方面的具体职责。
- 2020-12-24 20:235. **多平台支持**:wgcloud不仅适用于Linux,还可能支持Windows、Unix和其他操作系统,实现跨平台的统一监控。 6. **易安装与管理**:wgcloud的安装过程简单明了,官方网站www.wgstart.com提供了详细的安装指南,...
- 2023-03-20 09:58熟悉Linux系统的基本操作和命令,包括文件管理、进程管理、网络配置等。 对于大规模系统的管理,需要掌握自动化运维工具,如Ansible、SaltStack等。 网络安全是系统运维中非常重要的一环,需要掌握常见的攻击方式和...
- 2022-06-01 15:30在IT行业中,Linux运维是一项至关重要的任务,尤其在大规模企业环境中,有效管理和维护服务器集群是保证业务稳定运行的基础。在这个“Linux运维- 7....通过深入学习和实践,你将成为一名出色的Linux运维专家。
- 2023-11-29 10:37在Linux运维方面,需要具备以下技能:熟悉Linux操作系统的基本原理和命令行操作技能。熟练掌握不同的Linux发行版的安装、配置和调优。了解安全措施和防护措施,如使用防火墙、加密技术、认证和授权等。熟悉监控工具...
- 2025-08-28 20:55Linux作为一款开源的操作系统,其稳定性、灵活性以及高度可定制性使得其在服务器领域占据着不可撼动的地位。尤其在系统管理与网络运维领域,Linux以其丰富的命令行工具深受工程师们的青睐。本篇将深入探讨如何利用...
- 2025-09-25 12:00程序员羊羊的博客 第一个是知识付费类副业:输出经验打造个人IP 在线教育平台讲师 操作路径:在慕课网、极客时间等平台开设《CCNA实战》《Linux运维从入门到精通》等课程,或与培训机构合作录制专题课。 收益模式:课程销售分成、...
- 没有解决我的问题, 去提问


问题事件
 创建了问题
6月12日
创建了问题
6月12日