JavaIO流 FileReader 中 read() 方法读取一个中文返回的是 该中文的 Unicode 编码,那 FileInputStream 中 read() 方法读取中文返回的值到底代表什么意思 ?
文本文件 ->

java文件 ->


JavaIO流 FileReader 中 read() 方法读取一个中文返回的是 该中文的 Unicode 编码,那 FileInputStream 中 read() 方法读取中文返回的值到底代表什么意思 ?
文本文件 ->
java文件 ->
 分享
分享
 关注
关注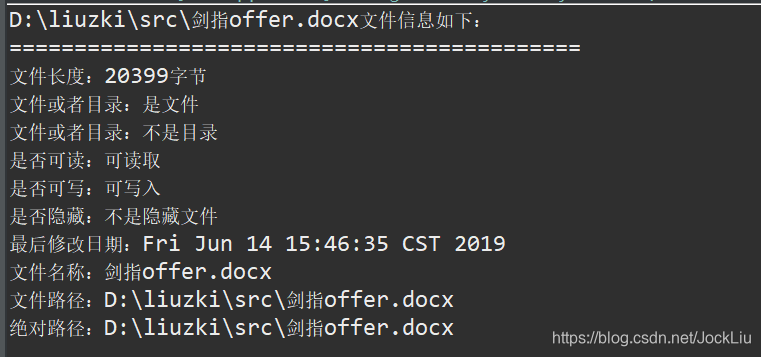
我们来看一下系统盘里具体信息:
O(∩_∩)O哈哈~,是不是两模一样呢!
根据参考资料中的代码和解释,可以得出以下结论:
FileInputStream的read()方法读取中文时,返回的是读取的字节数据,表示的是中文字符的字节编码。因为中文字符使用Unicode编码,一个中文字符通常占用两个字节或者更多字节,所以读取时返回的是字节数据。
具体来说,read()方法返回的是一个整数,该整数代表了读取的字节的ASCII码值。如果字节数据的高位字节是0,那么返回的整数即为字节的数值。如果字节数据的高位字节不是0,那么返回的整数只是低位字节的数值。
因此,如果要正确读取中文字符,需要使用read(byte[] b)方法,将读取到的字节数据存入一个字节数组中,然后将该字节数组转换为字符串,即可得到正确的中文字符。具体代码如下:
String filePath = "E:\\aba\\test03.txt";
FileInputStream fileInputStream = new FileInputStream(filePath);
byte[] buffer = new byte[1024];
int len;
while ((len = fileInputStream.read(buffer)) != -1) {
String str = new String(buffer, 0, len);
System.out.print(str);
}
fileInputStream.close();
在上述代码中,我们创建了一个字节数组buffer用来存储读取到的字节数据,然后将这个字节数组转换为字符串并打印出来。这样就能够正确读取中文字符了。
分享 创建了问题
7月2日
创建了问题
7月2日


