您好~ 请问您的精度是如何计算的?是否有加入其他数据训练,或者调参?
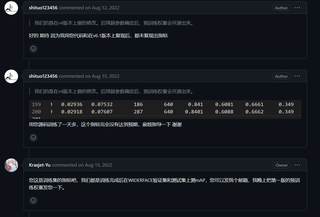

您好~ 请问您的精度是如何计算的?是否有加入其他数据训练,或者调参?
 分享
分享
 关注
关注【以下回答由 GPT 生成】
对于yolo face v2模型的精度计算可以使用准确率和召回率指标来评估模型的性能。具体计算步骤如下:
首先,准备测试集数据和标签。测试集数据包括待检测的图像,标签则为每张图像中人脸的真实边界框。
使用yolo face v2模型对测试集数据进行人脸检测,并获得模型的预测结果,即检测出的人脸边界框。
对于每个预测结果,计算其与对应标签的重叠程度。可以使用IoU(Intersection over Union)来度量重叠程度。IoU的计算公式如下:
python
IoU = Area of Overlap / Area of Union
其中,Area of Overlap为预测结果与标签的相交面积,Area of Union为预测结果与标签的并集面积。
设定一个阈值(如0.5),将重叠程度高于阈值的预测结果视为正确的检测结果,否则为错误的检测结果。
根据正确和错误的检测结果,计算准确率和召回率。
准确率(Precision)表示正确检测的人脸边界框占所有检测出的人脸边界框的比例。
python
Precision = TP / (TP + FP)
其中,TP为正确检测的人脸边界框数量,FP为错误检测的人脸边界框数量。
召回率(Recall)表示正确检测的人脸边界框占所有真实人脸边界框的比例。
python
Recall = TP / (TP + FN)
其中,TP为正确检测的人脸边界框数量,FN为未检测到的真实人脸边界框数量。
以上就是计算yolo face v2模型精度的一般步骤。要加入其他数据进行训练或进行调参,可以参考以下方法:
训练数据集:可以使用标记好的人脸数据集,如WIDER FACE数据集。该数据集包含了大量不同场景下的人脸图像和对应的标签,可以用于训练yolo face v2模型。
训练代码:yolo face v2模型的训练代码通常会提供在数据集上进行训练的功能。您可以通过修改训练代码中的参数来加入其他数据集进行训练,比如设置训练数据集的路径或修改数据加载的方式。
调参方法:调参可以包括调整学习率、增加训练迭代次数、修改网络结构等。具体的调参方法可以参考yolo face v2的文档或相关教程。一般来说,可以通过在一小部分训练数据上快速迭代,找到合适的超参数组合。然后再使用全部训练数据集进行训练。
这些是一般的方法和指导,具体的实施步骤可能会因为您的使用情况和需求而有所不同。如果您能提供更多关于您的使用情况和需求的细节,将有助于我们提供更具体和个性化的指导。
分享 创建了问题
10月15日
创建了问题
10月15日


