

有没有好朋友帮我解决一下Python的问题 是关于将图像转换为灰色图像的问题 出现的错误不知道是哪里出现了问题

 分享
分享
 关注
关注【相关推荐】
前言: 对于逻辑回归的决策边界有很多并不是线性的而是非线性的,那么这样我就需要训练非线性的逻辑回归,如何训练非线性的逻辑回归呢?仍然利用sklearn的特征转换思路,将非线性问题转为线性问题进行解决,具体思路
参考我这篇博文,关乎逻辑回归的理论知识 参考我这篇博文一、非线性逻辑回归解决分类问题Demo
import matplotlib.pyplot as plt
import numpy as np
from sklearn.metrics import classification_report
from sklearn import preprocessing
from sklearn.preprocessing import PolynomialFeatures
# 数据是否需要标准化
scale = False
# 读取数据
data = np.genfromtxt('LR-testSet2.txt', delimiter=',')
x_data = data[:, 0:-1]
y_data = data[:, -1, np.newaxis]
# 绘制各类别的数据散点图
def plotClass():
x0 = []
y0 = []
x1 = []
y1 = []
for i in range(len(x_data)):
if y_data[i] == 0:
x0.append(x_data[i, 0])
y0.append(x_data[i, 1])
else:
x1.append(x_data[i, 0])
y1.append(x_data[i, 1])
# 绘图
s1 = plt.scatter(x0, y0, c='b', marker='o')
s2 = plt.scatter(x1, y1, c='r', marker='x')
plt.legend(handles=[s1, s2], labels=['class0', 'class1'])
# 定义多项式回归,degree的值可以调节多项式的特征
poly_reg = PolynomialFeatures(degree=3) # 得到非线性方程y = theta0+theta1*x1+theta2*x1^2+theta3*x1*x2+theta4*x^2所需的样本数据
# 特征处理(获取多项式相应特征所对应的样本数据)
x_poly = poly_reg.fit_transform(x_data)
# 定义逻辑回归的模型函数(S型函数)
def sigmoid(x):
return 1 / (1 + np.exp(-x))
# 计算代价值
def cost(xMat, yMat, ws):
left = np.multiply(yMat, np.log(sigmoid(xMat * ws)))
right = np.multiply(1 - yMat, np.log(1 - sigmoid(xMat * ws)))
return np.sum(left + right) / -len(xMat)
# 梯度下降算法
def gradAscent(xArr, yArr):
if scale:
xArr = preprocessing.scale(xArr)
xMat = np.mat(xArr)
yMat = np.mat(yArr)
# 学习率
lr = 0.03
# 梯度下降迭代次数
ite = 50000
# 记录梯度下降过程中的代价值
costList = []
# 计算数据行列数
m, n = np.shape(xMat)
# 初始化线性函数权重
ws = np.mat(np.ones((n, 1)))
for i in range(ite + 1):
h = sigmoid(xMat * ws)
ws_grad = xMat.T * (h - yMat) / m
ws = ws - lr * ws_grad
if i % 50 == 0:
costList.append(cost(xMat, yMat, ws))
return ws, costList
# 训练模型
ws, costList = gradAscent(x_poly, y_data)
# 获取数据值所在的范围
x_min, x_max = x_data[:, 0].min() - 1, x_data[:, 0].max() + 1
y_min, y_max = x_data[:, 1].min() - 1, x_data[:, 1].max() + 1
# 生成网格矩阵
xx, yy = np.meshgrid(np.arange(x_min, x_max, 0.02), np.arange(y_min, y_max, 0.02))
# 测试点的预测值
z = sigmoid(poly_reg.fit_transform(np.c_[xx.ravel(), yy.ravel()]).dot(np.array(ws)))
print(xx.shape)
print(len(z))
for i in range(len(z)):
if z[i] > 0.5:
z[i] = 1
else:
z[i] = 0
z = z.reshape(xx.shape)
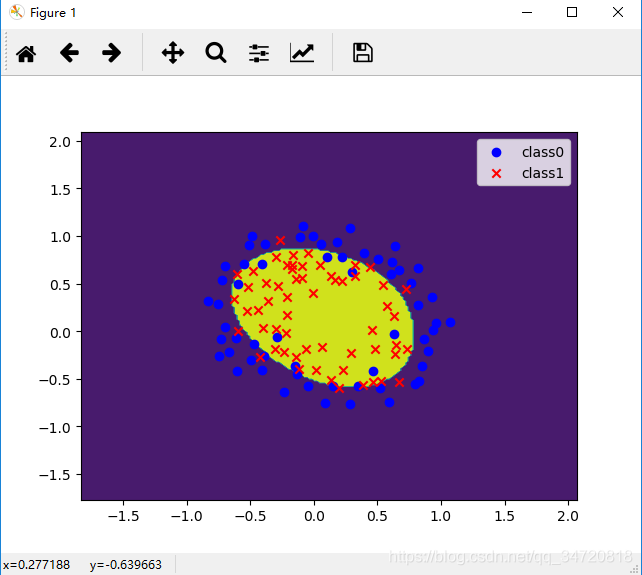
# 绘制等高线图
cs = plt.contourf(xx, yy, z)
plotClass()
# 根据训练的模型进行预测类型
def predict(x_data, ws):
if scale:
x_data = preprocessing.scale(x_data)
xMat = np.mat(x_data)
ws = np.mat(ws)
return [1 if x >= 0.5 else 0 for x in sigmoid(xMat * ws)]
predictions = predict(x_poly, ws)
# 计算准确率,召回率,F1值
print(classification_report(y_data, predictions))
plt.show()
二、执行结果
precision recall f1-score support
0.0 0.86 0.83 0.85 60
1.0 0.83 0.86 0.85 58
micro avg 0.85 0.85 0.85 118
macro avg 0.85 0.85 0.85 118
weighted avg 0.85 0.85 0.85 118
三、数据下载
链接:https://pan.baidu.com/s/1Lvrzw7s0d4F5jB7SVlkJzg
提取码:q3uv
分享 创建了问题
11月23日
创建了问题
11月23日

