
代码用了很多方面反反爬
随机IP池 随机请求头 验证码的处理 模拟人类行为爬等

 分享
分享
 关注
关注【相关推荐】
上面那个运行完毕之后,会在同一个文件夹下面出现一个ip.txt的文件,上面的可用的ip代理就在这个文件里面,如下:
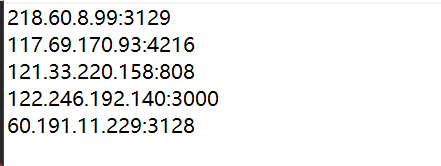
大家也许会觉得很少,但不要忘记我这里只是爬取了一页西祠代理上面可用的ip,然后,我用这些ip来访问了一下快代理,发现如下:

可以发现,运用这几个ip代理可以访问快代理这个网址到一千多页,如果不用ip代理,或许最多也只能访问一百多页吧!
代码如下:
import requests
with open(file='./ip.txt',mode='r',encoding='utf-8') as f:
str1=f.read()
list1=str1.split('\n')[:-1]
j=0
for i in range(1,3001):
try:
proxies={'https':list1[j]}
try:
response=requests.get(url='https://www.kuaidaili.com/free/inha/{}/'.format(i),proxies=proxies)
print(response.url)
print(response.status_code)
except:
j+=1
print('第{}ip开始'.format(j))
except:
print('所有代理已经全部使用!')
break
不用ip代理运行结果:

在访问这个网址时,发现如下,无论我怎样刷新都是这样,或许是ip被封了吧!

分享 创建了问题
12月8日
创建了问题
12月8日


