
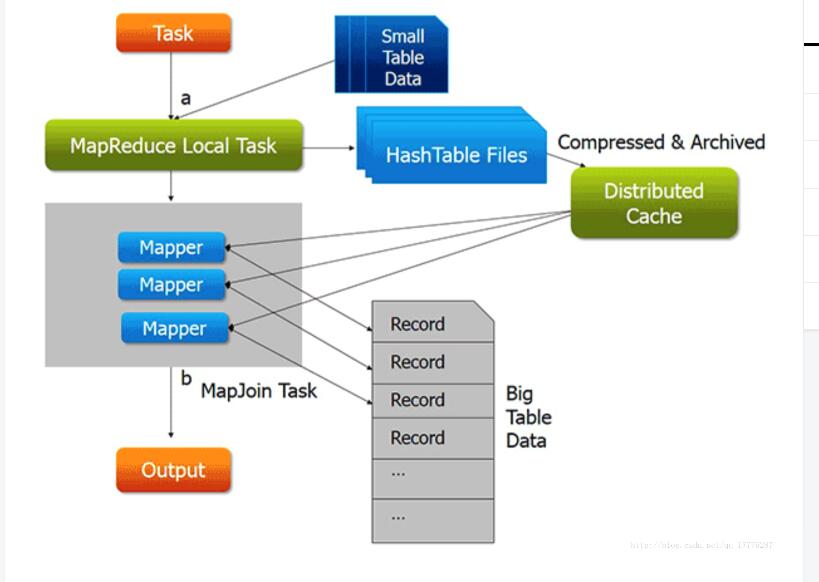

“把连接结果按key输出,经过shuffle阶段,reduce端得到的就是已经按key分组的,并且连接好了的数据”。
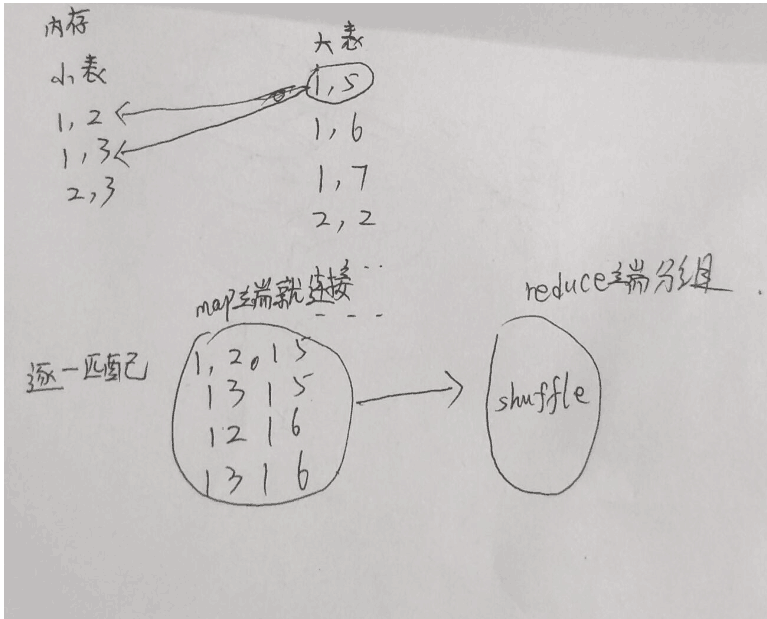
我理解为都是join,mapjoin在shuffle之前连接,reduce是shuffle之后连接
谁能举个例子吗,这样怎么就提高了效率呢,就因为shuffle前和shuffle后连接的区别导致的效率问题吗,这是适用与小表和大表连接的场景,顺便希望各路大佬帮忙说一下为什么reducejoin适合大表连接大表的场景,越详细越好,感谢回答问题的各位

“把连接结果按key输出,经过shuffle阶段,reduce端得到的就是已经按key分组的,并且连接好了的数据”。
我理解为都是join,mapjoin在shuffle之前连接,reduce是shuffle之后连接
谁能举个例子吗,这样怎么就提高了效率呢,就因为shuffle前和shuffle后连接的区别导致的效率问题吗,这是适用与小表和大表连接的场景,顺便希望各路大佬帮忙说一下为什么reducejoin适合大表连接大表的场景,越详细越好,感谢回答问题的各位
 分享
分享 已采纳回答
9月25日
已采纳回答
9月25日




