
- 在论文中,先取出n个任务,然后对每个任务,先计算在D_[i]^a上的损失,然后计算在D_[i]^a上更新后的模型参数,并使用该更新后的参数计算在D_[i]^b上的损失,最后将这两个损失进行加权求和,得到该任务的损失。将n个任务的损失加和去更新模型的参数。
- 但是在看网上的复现,发现并不符合这个流程:
复现1:

复现2:
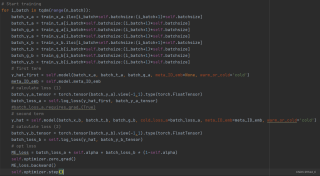
问题:
1. 他们都是将整个batch内的数据,当做一个任务,这是为什么?
2. 如果采用论文中的顺序,如何解决耗时过高的问题?

复现1:
复现2:
问题:
1. 他们都是将整个batch内的数据,当做一个任务,这是为什么?
2. 如果采用论文中的顺序,如何解决耗时过高的问题?
 分享
分享
引自微信小程序:皆我百晓生:
他们将整个batch内的数据视为一个任务是为了进行元学习。在元学习中,每个任务都包含了一组数据,通过在不同的任务上进行学习,模型可以学到泛化能力更强的表示。在算法1和算法2中,每个batch内的数据被看作是一个任务,通过在这个任务上进行学习,优化模型的参数,以使模型能够更好地适应不同任务的数据。
论文中提到的顺序采样方案确实可能导致耗时过高的问题。为了解决这个问题,可以采用一些加速方法,例如使用并行计算来同时处理多个任务,或者使用近似的优化算法来减少计算开销。另外,还可以对顺序采样进行优化,例如通过算法1中的随机采样n个任务,或者通过算法2中的分批采样,每次处理一批任务来减少耗时。这样可以有效地提高训练效率。
分享 已结题
(查看结题原因) 1月1日
修改了问题
12月25日
赞助了问题酬金15元
12月25日
修改了问题
12月22日
已结题
(查看结题原因) 1月1日
修改了问题
12月25日
赞助了问题酬金15元
12月25日
修改了问题
12月22日

