
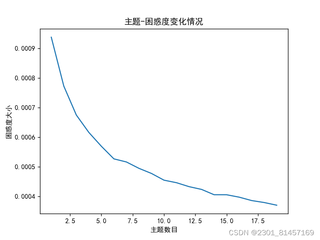
如图,下面代码运行结束后就出现了这种图像,一直是下降的,而且数值还很小,这种结果正常吗?还是说是因为代码出现了问题?
这是代码:
import gensim
from gensim import corpora, models
import matplotlib.pyplot as plt
import matplotlib
matplotlib.use('TkAgg')
from nltk.tokenize import RegexpTokenizer
from nltk.stem.porter import PorterStemmer
import math
# 准备数据
PATH = "分词文本.txt" # 已经进行了分词的文档(如何分词前面的文章有介绍)
file_object2 = open(PATH, encoding='utf-8', errors='ignore').read().split('\n')
data_set = [] # 建立存储分词的列表
for i in range(len(file_object2)):
result = []
seg_list = file_object2[i].split() # 读取没一行文本
for w in seg_list: # 读取每一行分词
result.append(w)
data_set.append(result)
print(data_set) # 输出所有分词列表
dictionary = corpora.Dictionary(data_set) # 构建 document-term matrix
corpus = [dictionary.doc2bow(text) for text in data_set]
Lda = gensim.models.ldamodel.LdaModel # 创建LDA对象
# 计算困惑度
def perplexity(num_topics):
ldamodel = Lda(corpus, num_topics=num_topics, id2word=dictionary, passes=50) # passes为迭代次数,次数越多越精准
print(ldamodel.print_topics(num_topics=num_topics, num_words=20)) # num_words为每个主题下的词语数量
print(ldamodel.log_perplexity(corpus))
return ldamodel.log_perplexity(corpus)
# 绘制困惑度折线图
x = range(1, 20) # 主题范围数量
y = [math.e**perplexity(i) for i in x]
plt.plot(x, y)
plt.xlabel('主题数目')
plt.ylabel('困惑度大小')
plt.rcParams['font.sans-serif'] = ['SimHei']
matplotlib.rcParams['axes.unicode_minus'] = False
plt.title('主题-困惑度变化情况')
plt.show()
```






