StandardScaler().fit(data).var_和data.var()输出结果不同,是为什么呢
看到有博主说:
num = StandardScaler().fit(data) #计算出矩阵每一列的均值和方差
print('data的均值:num1.mean_) #打印出矩阵每一列的均值
print('data的方差:num1.var_) #打印出矩阵每一列的方差
我就拿着数据试了下:
均值没问题:
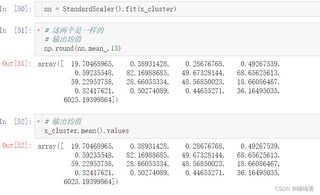
但是方差就对不上了:
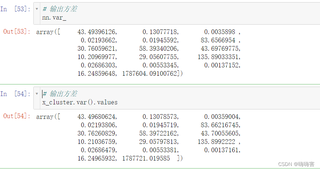
有大师解疑下嘛

StandardScaler().fit(data).var_和data.var()输出结果不同,是为什么呢
看到有博主说:
num = StandardScaler().fit(data) #计算出矩阵每一列的均值和方差
print('data的均值:num1.mean_) #打印出矩阵每一列的均值
print('data的方差:num1.var_) #打印出矩阵每一列的方差
我就拿着数据试了下:
均值没问题:
有大师解疑下嘛
 分享
分享
 关注
关注参考通义千问和郭老师的小迷弟雅思莫了-编写提供,主要是为了帮助您快速解决问题,如下回答,您可以参考下,如有问题,评论区留言。
StandardScaler() 是 Scikit-learn 中的一个预处理方法,它对数据进行标准化处理,即把数据按列(特征)缩放,使得每列数据都具有零均值和单位方差。这里的“单位方差”指的是经过变换后,每列数据的标准差变为1。
当你直接使用 data.var() 计算原始数据的方差时,得到的是未经标准化处理的各列特征的原始方差。
而当你使用 StandardScaler().fit(data).var_ 时,得到的是在标准化变换中计算出的新标准差的倒数(因为 var_ 属性存储的是每个特征的方差的逆,用于标准化过程中的除法操作)。因此,这个结果与原始数据的方差不同是正常的。
如果你想查看标准化后的数据的方差,可以对标准化后的数据做同样的方差计算:
scaler = StandardScaler()
scaled_data = scaler.fit_transform(data)
scaled_data.var()
此时得到的结果应该是接近于 [1, 1, ..., 1] 的形式(具体长度取决于特征数量),这是因为标准化的目标就是让变换后的数据具有单位方差。
分享 sklearn:sklearn.preprocessing.StandardScaler函数的fit_transform、transform、inverse_transform简介、使用方法之详细攻略
sklearn:sklearn.preprocessing.StandardScaler函数的fit_transform、transform、inverse_transform简介、使用方法之详细攻略 创建了问题
2月7日
创建了问题
2月7日
