hadoop python reduce运行出错code 1
下面是我的mapperG.py
import sys
for line in sys.stdin:
if not line: # Skip empty lines
continue
line = line.strip()
words = line.strip().split('->')
for i in range(0,len(words)-1):
if words[i]<words[i+1]:
print("{}\t{}".format(words[i]+words[i+1],0))
else:
print("{}\t{}".format(words[i + 1]+words[i], 1))
下面是我的reducerG.py
from operator import itemgetter
import sys
current_nodes = None
current_direct = -1
for line in sys.stdin:
line = line.strip()
try:
nodes, direct = line.split('\t', 1)
except ValueError:
# This handles lines that do not conform to the expected format
print(f"Error processing line: {line}", file=sys.stderr)
continue # Skip this line and move to the next
# Check if we're still processing the same pairs
if current_nodes == nodes:
if current_direct!=int(direct):
current_direct=2
else:
# Output the previous pairs
if current_nodes:
if current_direct!=2:
s = "{0} and {1} are in a one-way relationship".format(current_nodes[0], current_nodes[
1]) if current_direct == 0 else "{} and {} are in a one-way relationship".format(
current_nodes[1], current_nodes[0])
print(s)
# Reset for the new pairs
current_nodes = nodes
current_direct=int(direct)
# Output the last pairs after finishing all lines
if current_direct != 2:
s = "{0} and {1} are in a one-way relationship".format(current_nodes[0], current_nodes[
1]) if current_direct == 0 else "{} and {} are in a one-way relationship".format(
current_nodes[1], current_nodes[0])
print(s)
这是我的命令:
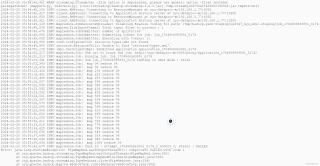
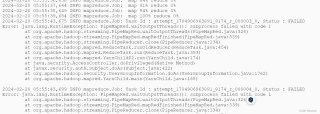
hadoop jar $HADOOP_HOME/hadoop-streaming-3.2.3.jar -input relations.txt -output outputG3 -mapper "python3 mapperG.py" -reducer "python3 reducerG.py" -file mapperG.py -file reducerG.py
input文件长这样

我用如下的命令运行是可以出结果的:
cat relations.txt|python mapperG.py|sort|python reducerG.py

然而一使用hadoop就报错: