
通过将年份和行业生成虚拟变量后,logit回归控制固定效应,样本量减少该如何解决?


2条回答 默认 最新

 关注
关注【相关推荐】
- 这篇博客: (2)stata的基本使用--分类回归 logit中的 .使用logit回归 部分也许能够解决你的问题, 你可以仔细阅读以下内容或跳转源博客中阅读:
估计 β\betaβ
函数形式:
P为y=1发生的概率,即每一类的概率

回归命令:
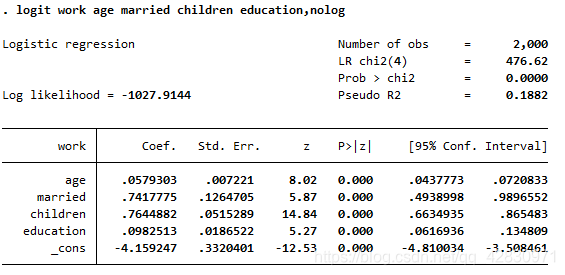
新概念Pseudo R2 表示准R方,

可以写为:

意味着:
(对数函数实际实际取值-只含常数项的对数取值)与(对数自然函数可能的最大取值-只含常数项的对数取值)之比,意味着加入分类变量能够让模型的准确的上升多少。回归结果的的解读:
LR为476.62,LR的P值检验是0.00000<0.05,说明方程整体是显著的,LR = n*R方 大样本下服从卡方分布
Pseudo R2 表示准R方:有0.1882,其含义类似于拟合优度
其coef为各自变量的系数β\betaβ,对应P值为各自显著性水平
$exp(\beta)$表示X每增加一单位,导致结果发生的概率比增加的倍数汇报 exp(β)exp(\beta)exp(β)的命令如下:
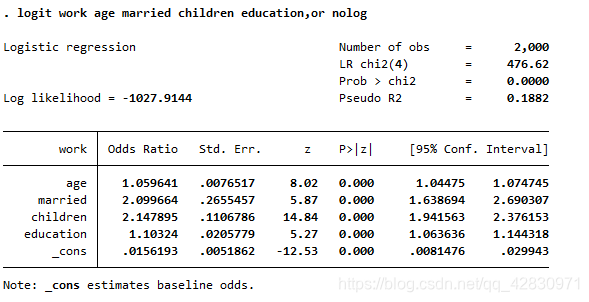
解释:以list the example of coefficient about married's and age's 已婚妇女参加工作的几率比是未婚妇女的2.099664倍(即高出109.9664%);年龄每增加一岁,参加工资的几率比增 加5.9641%,其他的变量类似解释are you 还 ok?哈哈,继续,如果你不相信这个模型,你可以使用logit稳健标准误差,向下看。
如果你已经解决了该问题, 非常希望你能够分享一下解决方案, 写成博客, 将相关链接放在评论区, 以帮助更多的人 ^-^解决 无用评论 打赏举报 分享
分享- 这篇博客: (2)stata的基本使用--分类回归 logit中的 .使用logit回归 部分也许能够解决你的问题, 你可以仔细阅读以下内容或跳转源博客中阅读:
- 2025-11-18 05:19魏献源Searcher的博客 在经济学和社科研究的海洋中,大数据分析往往面临着固定效应处理的巨大挑战。传统Stata命令在处理多层级固定效应时要么效率低下,要么功能有限。reghdfe的出现彻底改变了这一局面,为研究者提供了处理高维固定效应的...
- 2025-05-07 23:37拓端研究室TRL的博客 下面我们使用glmer命令估计混合效应逻辑回归模型,Il6、CRP和住院时间为患者水平的连续预测因素,癌症阶段为患者水平的分类预测因素(I、II、III或IV),经验为医生水平的连续预测因素,还有DID的随机截距,医生ID。
- 2024-09-11 17:17宝书研习社的博客 oneclick 命令为复杂回归分析中的控制变量筛选提供了一种高效、便捷的解决方案。通过自动化处理,oneclick 能够快速筛选出符合显著性要求的变量组合,帮助用户节省大量时间,并确保分析结果的稳健性。其位图算法的...
- 2024-04-23 17:55拓端研究室TRL的博客 然而,随之而来的欺诈行为也日益猖獗,给求职者带来了极大的困扰和风险(点击文末“阅读原文”获取完整代码数据)。视频因此,如何帮助客户有效地识别和防范招聘网站上的欺诈行为,已成为一个亟待解决的问题。逻辑...
- 2025-10-23 16:11数据科学作家的博客 文章详细比较了Stata(命令行高效)和SPSS(菜单交互)的操作差异,并推荐了多本实用教材,包括《Stata统计分析从入门到精通》《SPSS统计学与案例应用精解》等。这些教材涵盖基础操作到高级应用,配有案例数据和教学...
- 2026-02-10 13:58paperxie论文的博客 paperxie 的数据分析功能,正是为了解决上述痛点而设计。研究信息填写数据文件上传和输出结果,形成了一个闭环的、一站式的解决方案。在学术研究的道路上,数据不应该是阻碍你前进的泥潭,而应该是支撑你结论的基石...
- 2020-10-20 19:42weixin_39849888的博客 所以小伙伴们可以择优选择,放入自己的购物车中~STATA软件优点:Stata以其简单易懂和功能强大受到初学者和高级用户的普遍欢迎。使用时可以每次只输入一个命令,也可以通过一个Stata程序一次输入多个命令。这样的话.....
- 2020-12-30 13:26前任一米五的博客 1月25日上午主讲人:邓旭东课程安排:python语法入门1、Python跟英语一样是一种语言2、数据类型之字符串3、数据类型之列表元组集合4、数据类型之字典5、数据类型之布尔值、None6、逻辑语句(if&for&tryexcept...
- 2020-11-22 17:19weixin_39860064的博客 盲区行者:深度学习之BP神经网络--Stata和R同步实现(附R数据和代码)zhuanlan.zhihu.com原公众号推文标题:深度学习之BP神经网络-Stata和R同步实现(附数据和代码)神经网络(Neural Network,或Artif...
- 2021-12-20 19:37兔小包包的博客 第二章 数据结构与基本运算 2.1 数据类型 数值型(numeric) 整数 小数 科学数 字符型(character) == 夹杂单引号或者双引号之间==“MR” 逻辑型 ==只能读取T (TRUE)或 F (FALSE)值 复数型 a+bi 原始型(raw) 以...
- 2024-07-27 00:30林聪木的博客 1. 二元响应变量(Binary Response Variable)Probit回归分析的因变量(响应变量)是二元的,即它只有两个可能的值,通常表示为0和1,或者成功与失败。2. 自变量(Independent Variables)自变量是影响二元响应变量...
- 2025-12-16 11:05StepLens的博客 掌握临床数据的因果推断难题?本文深入解析5大经典算法在R语言中的实现路径,涵盖匹配、IPW、双重差分等核心方法,适用于观察性研究与真实世界证据分析。比较各算法优劣与适用场景,助力精准医学决策,值得收藏。
- 2025-12-23 14:08虎贲等考教育的博客 数据分析是论文写作中最棘手的环节之一,技术门槛高、逻辑要求严、格式规范繁琐。虎贲等考AI(官网:https://www.aihbdk.com/)推出学术级数据分析功能,提供全类型分析覆盖、零代码操作、自动检验流程和深度结果...
- 2025-10-30 03:59v5w6x的博客 通过一个完整的“共享单车 vs 电动滑板车”实战案例,详细演示了从实验设计、数据收集、模型估计到结果解读与业务洞察的完整工作流,并分享了关键的避坑指南与高阶技巧,帮助读者掌握这一解码人类选择行为的强大工具...
- 2021-05-04 10:01youcans的博客 关于 StatsModels statsmodels(http://www.statsmodels.org)是一个Python库,用于拟合多种统计模型,执行统计测试以及数据探索和...具有混合效应和方差分量的混合线性模型 glm:支持所有一个参数的广义线性模型 指.
- 2020-12-27 11:32拓端研究室的博客 混合模型的输出将给出一个解释值列表,其效应值的估计值和置信区间,每个效应的p值以及模型拟合程度的至少一个度量。如果您有一个变量将您的数据样本描述为您可能收集的数据的子集,则应该使用混合模型而不是简单的...
- 2025-12-31 18:08BreakVein的博客 掌握R语言混合效应模型实现方法,解决重复测量与分层数据建模难题。涵盖线性与广义模型、随机效应设定、模型比较与诊断,适用于生物医学、社会科学等多领域。语法清晰、结果可靠,显著提升分析精度,值得收藏。
- 2022-09-21 16:00拓端研究室TRL的博客 当前教程特别关注贝叶斯逻辑回归在二元结果和计数/比例结果场景中的使用,以及模型评估的相应方法。使用教育数据示例。此外,本教程简要演示了贝叶斯 GLM 模型的多层次扩展。相关视频=本教程遵循以下结构:1.准备...
- 2023-03-10 14:20拓端研究室TRL的博客 原文链接:http://tecdat.cn/?p=967对于某企业新...相关视频:R语言逻辑回归(Logistic回归)模型分类预测病人冠心病风险逻辑回归Logistic模型原理和R语言分类预测冠心病风险实例,时长06:48对于付费用户预测,主...
- 2020-06-02 10:35大太阳小白的博客 线性模型 概念:试图学得一个通过属性的线性组合来进行预测的函数 形式: 可解释性: 性能度量 常用性能度量均方误差: ...中国平安和沪深300指数的日收益率数据,使用中国平安收益率作为特征收入,沪深30
- 没有解决我的问题, 去提问

问题事件
 创建了问题
3月25日
创建了问题
3月25日