关于k8s node节点被释放后如何驱逐节点并添加新节点 谁有搭建抢占式k8s服务器的经验。请有相关经验的来回答

如使用驱逐命令也是驱逐不了的
kubectl drain k8s-node2 --ignore-daemonsets

强制驱逐并且删除数据的方法也试过了。
kubectl drain k8s-node2 --ignore-daemonset --delete-emptydir-data --force
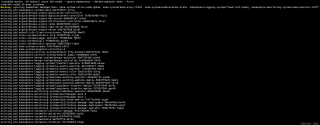
一直会运行这样,一个小时后也是一样的输出,就是驱逐不了。
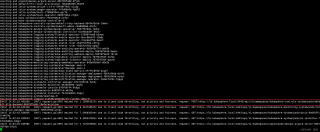

关于k8s node节点被释放后如何驱逐节点并添加新节点 谁有搭建抢占式k8s服务器的经验。请有相关经验的来回答
如使用驱逐命令也是驱逐不了的
kubectl drain k8s-node2 --ignore-daemonsets
强制驱逐并且删除数据的方法也试过了。
kubectl drain k8s-node2 --ignore-daemonset --delete-emptydir-data --force
 分享
分享
 关注
关注引自免费微信小程序:皆我百晓生
针对您遇到的问题,即在Kubernetes集群中无法成功驱逐节点k8s-node2,即使使用了kubectl drain命令并附加了--ignore-daemonsets、--delete-emptydir-data和--force选项,且节点状态为NotReady及SchedulingDisabled,您报告的输出表明存在一些阻碍节点成功驱逐的因素。为了解决这个问题,您可以尝试以下步骤:
检查节点状况:
首先,确保k8s-node2节点上没有正在运行的Pod。您已尝试了驱逐命令,但输出显示仍有多个Pod未能被成功驱逐。这可能是由于Pod处于异常状态(例如,Pending、CrashLoopBackOff等)导致的。请使用以下命令查看节点上所有Pod的状态:
kubectl get pods --all-namespaces -o wide | grep "k8s-node2"
如果发现有异常状态的Pod,可能需要手动清理或调整这些Pod。
处理残留Pod: 对于无法正常驱逐的Pod,可能需要采取以下措施:
确认Pod是否有本地磁盘依赖: 如果Pod使用了本地存储(如HostPath卷),驱逐时可能会因为数据丢失风险而失败。请检查Pod的YAML定义,确认是否有这类卷。如果有,可能需要手动备份数据或调整Pod配置使用持久化存储。
检查Pod的重启策略:
如果Pod的重启策略设置为Always,且容器无法正常启动,它会持续进入Pending状态,阻碍驱逐。可以暂时将这些Pod的重启策略改为OnFailure或Never,待节点驱逐后再恢复。
强制删除Pod: 对于无法正常驱逐的Pod,可以尝试强制删除:
kubectl delete pod <pod-name> --grace-period=0 --force --namespace=<namespace>
检查节点锁定情况: 确认节点是否被其他Kubernetes操作(如节点维护、节点升级等)锁定,导致无法驱逐。可以使用以下命令查看节点的锁定状态:
kubectl get node k8s-node2 -o jsonpath='{.metadata.annotations.kubernetes\.io/lock\-holder}'
如果返回非空值,表示节点被锁定。解除锁定后,再尝试驱逐节点。
排查网络问题: 确保节点间的网络通信正常,因为网络问题可能导致节点驱逐命令无法有效执行。检查节点间ping通性、Kubernetes API Server与节点之间的通信等。
检查节点控制器: 确保节点控制器(Node Controller)工作正常,没有因异常导致节点状态更新滞后。可以在Kubernetes控制面板或日志中查看节点控制器状态和日志。
升级或重置Kubernetes组件: 如果上述方法都无法解决问题,可能是Kubernetes集群组件(如API Server、kubelet等)存在bug或配置问题。尝试升级到最新稳定版本,或者重置受影响的组件。
综上所述,通过仔细排查节点状态、残留Pod、节点锁定、网络问题以及节点控制器状态,应该能找到阻碍节点驱逐的原因,并针对性地进行解决。在完成上述步骤后,再次尝试使用驱逐命令:
kubectl drain k8s-node2 --ignore-daemonsets --delete-emptydir-data --force
如果问题依然存在,请提供详细的节点日志、Pod描述信息以及Kubernetes组件日志,以便进一步分析。
分享 已结题
(查看结题原因) 4月18日
修改了问题
4月18日
修改了问题
4月17日
修改了问题
4月17日
已结题
(查看结题原因) 4月18日
修改了问题
4月18日
修改了问题
4月17日
修改了问题
4月17日




