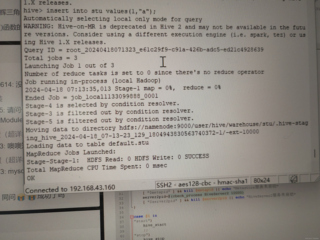
请求回答,插入数据时没有报错但是map和reduce都为0,数据没有被读入和写入,最后查询时依然没有查询到所插入的数据。
这种情况该怎么解决啊?

 分享
分享
 关注
关注引自免费微信小程序:皆我百晓生
面对你在Hive中遇到的问题,即数据插入后在执行查询时仍然找不到数据,且MapReduce任务数为0,这通常可能由于以下几个原因导致:
default)中。为了排查并解决这个问题,可以按照以下步骤操作:
**步骤一:**首先确认表是否存在以及其结构:
DESCRIBE FORMATTED default.stu;
如果表不存在,你需要先创建表:
CREATE TABLE IF NOT EXISTS default.stu (
id INT,
name STRING
);
**步骤二:**检查插入的数据是否符合表结构的要求。例如,如果表中有id(int)和name(string)两个字段,那么插入的数据应为(1, "a")这样的格式。
INSERT INTO default.stu VALUES (1, "a");
**步骤三:**确认是否有足够的权限进行写入操作。如果你不是管理员,可以尝试使用GRANT命令赋予相应的权限。
GRANT ALL PRIVILEGES ON TABLE default.stu TO [your_username];
**步骤四:**确认Hive的执行引擎设置。Hive默认使用的是Hive on MR,但这个已经被弃用。你可以通过以下命令查看当前的执行引擎:
SET mapred.job.tracker;
如果输出结果是local, 那么说明正在使用本地模式。要切换到其他执行引擎(如Spark),你需要在Hive的配置文件(通常是hive-site.xml)中更改hive.execution.engine属性。如果你的集群启用了Spark,可以在Hive客户端运行以下命令:
SET hive.exec.mode=spark; -- 设置为Spark执行引擎
**步骤五:**重启Hive服务,让新的配置生效。然后再次尝试插入数据并查询。
如果你的集群启用了YARN,确保HiveServer2服务已经启动。你可以通过以下命令检查:
jps | grep HiveServer2
如果没有返回任何结果,启动HiveServer2:
sbin/start-hiveserver2.sh
如果你的集群启用了Kerberos,确保你已经登录了Kerberos并设置了适当的环境变量。
执行上述步骤后,你应该能成功插入数据并能在查询中找到它。如果还有问题,请提供更详细的错误信息以便进一步诊断。
分享 Hive第一天:Hive入门、优缺点、Hive架构原理、Hive下载安装、Hive元数据配置MySQL、Hive常用命令、Hive属性配置、Hive数据类型、DDL数据定义、Hive对数据库的增删改查
Hive第一天:Hive入门、优缺点、Hive架构原理、Hive下载安装、Hive元数据配置MySQL、Hive常用命令、Hive属性配置、Hive数据类型、DDL数据定义、Hive对数据库的增删改查 创建了问题
4月17日
创建了问题
4月17日
