
不知道按了什么键,就不能输入了,要输入只能按enter,然后只能输入,不能删除,也不能把光标移动位置

不知道按了什么键,就不能输入了,要输入只能按enter,然后只能输入,不能删除,也不能把光标移动位置
 分享
分享
以下内容由CHATGPT及阿里嘎多学长共同生成、有用望采纳:
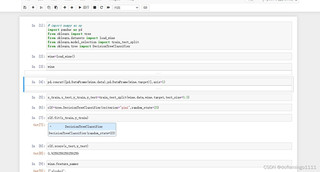
图片内容显示了一段在Jupyter Notebook中执行的Python代码,这段代码主要涉及使用pandas和sklearn库进行葡萄酒数据集的加载、数据分割、决策树分类器的创建和训练,以及模型的评估。代码中存在一些语法错误,例如pd. DataFrane应该是pd.DataFrame,wine. data和wine. target中的点号.应该是逗号,。
用户在Jupyter Notebook中遇到了文本输入问题,无法正常输入文字,只能使用回车键,且无法删除文本或移动光标位置。
这个问题可能是由于Jupyter Notebook的内核或前端出现了某些问题,或者是用户的误操作导致输入模式被切换了。在Jupyter Notebook中,有两种模式:命令模式(Command Mode)和编辑模式(Edit Mode)。在命令模式下,用户可以使用键盘快捷键执行操作,但不能编辑单元格内容;在编辑模式下,用户可以编辑单元格内容。
检查模式:确保你处于编辑模式(Edit Mode)。通常,单元格左上角会显示“In [x]”表示处于编辑模式。
重置内核:如果确认处于编辑模式但仍然无法输入,可以尝试重置内核。在Jupyter Notebook的菜单栏中选择“Kernel” -> “Restart & Run All”。
检查浏览器:确保浏览器没有被禁用JavaScript,因为Jupyter Notebook依赖JavaScript来运行。
浏览器插件:检查是否有浏览器插件或扩展影响了Jupyter Notebook的正常工作。
清除缓存:清除浏览器缓存或尝试使用不同的浏览器。
键盘快捷键:尝试使用键盘快捷键Esc退出命令模式,然后按Enter进入编辑模式。
由于用户遇到的问题与代码执行无关,因此无需提供修改后的代码。但是,以下是修正了语法错误的原始代码:
# import necessary libraries
import numpy as np
import pandas as pd
from sklearn import tree
from sklearn.datasets import load_wine
from sklearn.model_selection import train_test_split
from sklearn.tree import DecisionTreeClassifier
# Load wine dataset
wine = load_wine()
# Create a DataFrame from the dataset
wine_df = pd.concat([pd.DataFrame(wine.data, columns=wine.feature_names), pd.DataFrame(wine.target, columns=['target'])], axis=1)
# Split the dataset into training and testing sets
x_train, x_test, y_train, y_test = train_test_split(wine.data, wine.target, test_size=0.3, random_state=23)
# Create a Decision Tree classifier
clf = DecisionTreeClassifier(criterion='gini', random_state=23)
# Fit the classifier to the training data
clf.fit(x_train, y_train)
# Evaluate the classifier on the test data
accuracy = clf.score(x_test, y_test)
print("Accuracy:", accuracy)
# Print the feature names
print("Feature names:", wine.feature_names)
要运行上述代码,你需要有Python环境,并且安装了numpy, pandas, sklearn这些库。你可以在Jupyter Notebook中直接运行这段代码。
如果代码正确执行,你将看到决策树分类器在测试集上的准确率,以及葡萄酒数据集的特征名称。例如:
Accuracy: 0.9259259259259259
Feature names: ['feature1', 'feature2', ..., 'feature13']
请注意,特征名称将由实际的葡萄酒数据集特征名称代替。
分享 系统已结题
5月7日
系统已结题
5月7日 已采纳回答
4月29日
创建了问题
4月23日
已采纳回答
4月29日
创建了问题
4月23日

