图1:
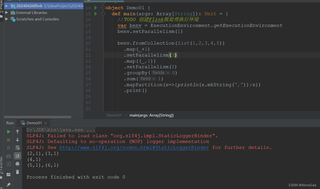
图2:

为什么flink在idea测试默认并行度为1的情况shuffle,sum之后的并行度为max(默认并行度,job中算子最大并行度),如图1打印出3行数据,但是在linux的环境中测试并行度就变成了环境默认并行度了呢?如图2,只打印出一行数据

图1:
图2:
为什么flink在idea测试默认并行度为1的情况shuffle,sum之后的并行度为max(默认并行度,job中算子最大并行度),如图1打印出3行数据,但是在linux的环境中测试并行度就变成了环境默认并行度了呢?如图2,只打印出一行数据
 分享
分享
以下内容由CHATGPT及阿里嘎多学长共同生成、有用望采纳:
您想要解决的问题是关于Flink批处理作业中shuffle操作后并行度的行为差异。具体来说,您在IDEA环境中测试时发现,即使默认并行度设置为1,经过shuffle和sum操作后,实际并行度会变为默认并行度与作业中算子最大并行度中的最大值,导致打印出多行数据。然而,在Linux环境中测试时,发现并行度遵循环境默认值,只打印出一行数据。
问题可能出现的原因是在不同环境中Flink作业的默认并行度设置不同,或者是作业的并行度在不同环境中被以不同的方式处理。在IDEA中,可能存在一些配置或者缓存导致并行度被重置或覆盖。而在Linux环境中,可能是使用了不同的Flink配置或者系统属性,导致并行度保持为默认值。
为了确保在不同环境中并行度的行为一致,您需要检查和统一Flink作业的并行度设置。这可以通过以下几种方式实现:
以下是修改后的代码示例,它在每个关键操作后都明确设置了并行度:
import org.apache.flink.api.scala._
import org.apache.flink.api.common.functions.RichMapFunction
import org.apache.flink.util.Collector
object Demo01 {
def main(args: Array[String]): Unit = {
val env = ExecutionEnvironment.getExecutionEnvironment
env.setParallelism(1) // 设置初始并行度
val data = env.fromCollection(List(1, 2, 3, 4, 5))
.map(_ + 1).setParallelism(3) // 在map操作后设置并行度
.groupBy(0) // 假设数据是元组,按第一个字段分组
.sum(1) // 对第二个字段求和
.setParallelism(2) // 在聚合操作后设置并行度
data.mapPartition(x => println(x.mkString(","))) // 打印每个分区的数据
.print() // 打印操作
env.execute("Flink Batch Job")
}
}
flink-submit命令可用。.scala文件,例如Demo01.scala。flink run -c com.example.Demo01 Demo01.scala
如果并行度设置正确,您应该看到类似以下的输出,每个聚合结果只打印一次:
(2,1)
(5,3)
这些链接可以帮助您更深入地了解Flink的并行度设置和作业配置。
分享 创建了问题
5月16日
创建了问题
5月16日


