执行hiveonspark的sql之后,数据成功插入进去了,但是yarn中的任务一直running状态,executors中有一个task一直卡死,求解答

执行hiveonspark的sql之后,数据成功插入进去了,但是yarn中的任务一直running状态,executors中有一个task一直卡死,求解答
 分享
分享
以下内容由CHATGPT及阿里嘎多学长共同生成、有用望采纳:
【您想要解决的问题】:您提问的目的是解决在使用Hive on Spark执行SQL任务后,虽然数据已成功写入,但在YARN中的任务持续处于运行状态,且有一个Executor中的Task一直卡住不前进的问题。
【图片内容】:
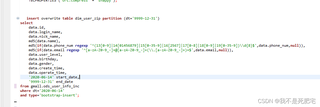
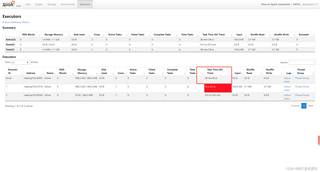
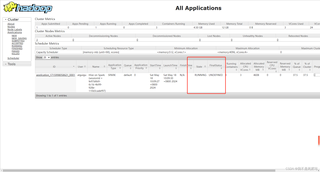
dim_user_zip表中插入数据,并指定了分区为'9999-12-31'。SQL中包含了对数据进行MD5加密和正则表达式匹配的操作。application_1715998058621_0001的Hive on Spark应用程序正在运行。【问题出现原因】:问题可能出现的原因有多种,以下是一些可能的原因:
【问题解决方案】:
【提供代码】:由于问题可能与具体的SQL查询或数据有关,这里不提供具体的代码,而是建议对SQL查询进行优化,例如:
【代码运行方式】:优化后的SQL查询可以在Spark SQL或Hive环境中执行。确保你的Spark集群有足够的资源,并且已经根据需要调整了作业的配置参数。
【代码预期运行结果】:优化后的代码应该能够提高作业的处理速度,减少Executor的卡顿现象。
【推荐相关链接】:
分享 创建了问题
5月18日
创建了问题
5月18日

