
问题如下:
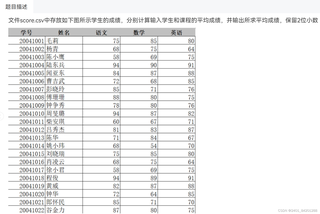


代码如下:

要求以批注的形式逐行解读该代码的含义,不要另写代码。

问题如下:
代码如下:
要求以批注的形式逐行解读该代码的含义,不要另写代码。
 分享
分享
以下内容由CHATGPT及阿里嘎多学长共同生成、有用望采纳:
根据提供的图片内容,下面是对Python代码的逐行批注解读:
1 f·=·open("score.csv",·"r",·encoding·=·"utf-8")
# 打开名为"score.csv"的文件用于读取,使用utf-8编码。
2 It=.[]
# 初始化一个空列表It,可能这里应该是lt=[],用于存储文件中的每一行数据。
3 for.s in·f:
# 遍历文件f中的每一行数据。
4 .·lt.append(s.replace("\n",."").split(","))
# 将每行数据去除换行符后,以逗号分隔并添加到列表lt中。
5 courses·=·lt[0][2:]
# 将lt列表中第一行(假设为课程名称)的第2个元素及之后的元素赋值给courses。
6 dic·=·
# 初始化一个空字典dic,用于存储学生的成绩数据。
7 for.i.in.lt[1:]:
# 从lt列表的第二行开始遍历(第一行是标题行,假设不包含数据)。
8 ..·dic[i[1]]·=.list(map(int,·i[2:]))
# 将学生的姓名作为键,对应的成绩列表(转换为整数)作为值,存储到字典dic中。
9 name,·course·=·inputO.split)
# 这里应该是name, course = input().split(),从用户输入中获取学生姓名和课程名称,并分割。
10 if·name·in·dic.keys() :
# 检查输入的学生姓名是否存在于字典dic的键中。
11 .··mean·=·sum(dic[name]·/.len(dic[name])
# 计算该学生的平均成绩,这里应该是mean = sum(dic[name]) / len(dic[name])。
12 ...print("该学生平均成绩为:.2f}\".format(mean))
# 输出学生的平均成绩,格式化为保留两位小数。这里应该是print("该学生平均成绩为:{:.2f}".format(mean))。
13 else:
# 如果学生姓名不在字典的键中。
14 ·print("没有该学生")
# 输出"没有该学生"。
15 if.course·in·courses:
# 检查输入的课程名称是否存在于courses列表中。
16 ...i·=·courses.index(course)
# 获取课程名称在courses列表中的索引。
17 ...sl·=.[k[i].fork in·dic.values()]
# 这行代码有误,意图可能是获取所有学生该课程的成绩列表,但需要修正。
18 .....mean·=·sum(s1)·/.len(s1)
# 计算该课程的平均成绩,这里应该是mean = sum(s1) / len(s1)。
19 print("该课程平均成绩为{:.2f".format(mean))
# 输出课程的平均成绩,格式化为保留两位小数。这里应该是print("该课程平均成绩为{:.2f}".format(mean))。
20 else:
# 如果输入的课程名称不在courses列表中。
21 ·print("没有该课程")
# 输出"没有该课程"。
# 代码最后有CSDN作者的标识。
请注意,代码中存在一些明显的错误和不规范的写法,如变量名错误(It应为lt)、函数名错误(inputO应为input)、缺失的括号和引号等。此外,第17行的代码意图不明确且有语法错误,需要根据实际需求进行修正。
分享 系统已结题
6月12日
系统已结题
6月12日 已采纳回答
6月4日
创建了问题
6月4日
已采纳回答
6月4日
创建了问题
6月4日


