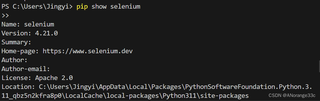
可以帮我看看为什么运行不了吗?
想要实现的目的:根据企业代码.xlxs里的企业名单在巨潮资讯网搜索2023年年度报告并下载
代码:
import os
import time
from selenium import webdriver # type: ignore
from selenium.webdriver.common.keys import Keys # type: ignore
from openpyxl import load_workbook # type: ignore
from selenium.webdriver.chrome.service import Service # type: ignore
# 读取企业代码
def read_company_codes(file_path):
wb = load_workbook(file_path)
ws = wb.active
company_codes = []
for row in ws.iter_rows(min_row=2, values_only=True):
company_codes.append((row[0], row[1]))
return company_codes
# 下载年报
def download_annual_reports(company_codes):
service = Service('C:\Program Files\ESBrowser\chromedriver.exe')
driver = webdriver.Chrome(service=service)
driver.get("http://www.cninfo.com.cn/new/index")
for code, name in company_codes:
# 搜索年报
search_box = driver.find_element_by_id("searchKeyword")
search_box.clear()
search_box.send_keys(code)
search_box.send_keys(Keys.ENTER)
# 选择分类-年报
annual_reports_link = driver.find_element_by_xpath("//a[contains(text(), '年报')]")
annual_reports_link.click()
# 下载年报
download_button = driver.find_element_by_xpath("//a[contains(text(), '下载')]")
download_button.click()
# 等待下载完成
time.sleep(5)
# 重命名文件
old_file_path = "D:\\数据采集\\年报\\" + code + ".pdf"
new_file_path = "D:\\数据采集\\年报\\" + code + "_" + name + ".pdf"
os.rename(old_file_path, new_file_path)
driver.quit()
配置环境:pyhton3.11.9 64bit
1.

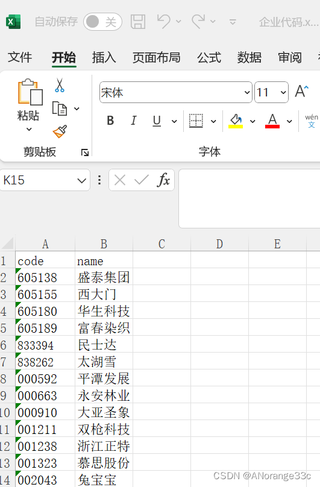
2.企业代码.xlxs的数据结构
3.selenium.库