该怎么修改这个代码才能运行正常呢,要如何处理这个问题呢,为什么会出现这种情况
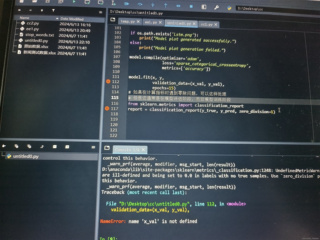

该怎么修改这个代码才能运行正常呢,要如何处理这个问题呢,为什么会出现这种情况
 分享
分享
 关注
关注引自免费微信小程序:皆我百晓生
从你提供的信息来看,主要的问题在于NameError: name 'x_val' is not defined,这意味着在你的代码中使用了变量x_val,但在执行到相关行之前它并未被定义。为了解决这个问题,你需要确保所有使用的变量都在被调用前已经定义。
定义变量:确保x_val和y_val已经被正确定义。这些变量通常来自于数据集的分割,比如使用train_test_split函数从sklearn.model_selection模块中导入。
检查数据分割:确认x_val和y_val的数据是否正确无误,它们应该是训练数据集之外的验证数据集的一部分。
代码示例:下面是一个如何定义和使用x_val和y_val的示例代码。假设你有X作为特征数据和y作为标签数据:
from sklearn.model_selection import train_test_split
# 假设X是特征数据,y是标签数据
# 这里我们使用80%的数据进行训练,20%的数据进行验证
X_train, X_val, y_train, y_val = train_test_split(X, y, test_size=0.2, random_state=42)
# 现在我们可以使用X_train和y_train进行模型训练
# 使用X_val和y_val进行验证
X_train, X_val, y_train, y_val替换为实际的变量名,然后在model.fit()中使用正确的变量名。如果你还没有进行数据分割,可以尝试以下代码:
import numpy as np
from sklearn.model_selection import train_test_split
from tensorflow.keras.models import Sequential
from tensorflow.keras.layers import Dense
# 创建示例数据
X = np.random.rand(100, 10) # 100个样本,每个样本10个特征
y = np.random.randint(0, 2, size=100) # 二分类问题
# 数据分割
X_train, X_val, y_train, y_val = train_test_split(X, y, test_size=0.2, random_state=42)
# 构建模型
model = Sequential()
model.add(Dense(32, activation='relu', input_dim=10))
model.add(Dense(1, activation='sigmoid'))
# 编译模型
model.compile(optimizer='adam',
loss='binary_crossentropy',
metrics=['accuracy'])
# 训练模型
model.fit(X_train, y_train,
validation_data=(X_val, y_val),
epochs=15, batch_size=32)
请根据你的具体需求调整上述代码中的数据创建、模型结构以及训练参数。如果y包含多个类别,你可能需要使用to_categorical函数转换y,并相应地调整损失函数和输出层的激活函数。
分享 系统已结题
6月21日
系统已结题
6月21日 已采纳回答
6月13日
创建了问题
6月13日
已采纳回答
6月13日
创建了问题
6月13日

