这是我准备绘图的时候出现的一个问题,不知道该怎么办了,是我的数组本身的问题吗

这是我准备绘图的时候出现的一个问题,不知道该怎么办了,是我的数组本身的问题吗
 分享
分享
 关注
关注引自免费微信小程序:皆我百晓生
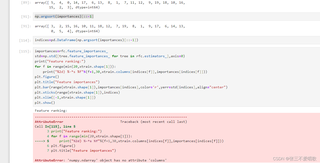
从你提供的信息来看,错误信息'numpy.ndarray' object has no attribute 'columns'提示你在尝试访问一个NumPy数组的columns属性时遇到了问题。通常,columns属性是pandas DataFrame对象所拥有的,而不是NumPy数组的属性。
在你的代码中,你尝试通过xtrain.columns[indices[f]]访问列名,这表明xtrain可能应该是一个pandas DataFrame,而不是一个NumPy数组。为了确保xtrain是DataFrame类型,你需要检查xtrain的类型,并确保它是由pandas库创建的。
为了解决这个问题,你可以按照以下步骤操作:
确认xtrain是pandas DataFrame类型。你可以通过运行以下代码来检查:
print(type(xtrain))
如果xtrain不是DataFrame类型,你需要将其转换为DataFrame。假设xtrain目前是一个NumPy数组,你可以通过以下方式将其转换为DataFrame:
xtrain = pd.DataFrame(xtrain)
如果xtrain已经是DataFrame类型,但是缺少列名,你需要为其添加列名。假设你有n个特征,你可以使用以下代码添加默认列名:
xtrain.columns = [f"feature_{i}" for i in range(n)]
修改你的代码以确保xtrain被正确处理。更新后的代码如下所示:
indices = np.argsort(importances)[::-1]
importances = rfc.feature_importances_
std = np.std([tree.feature_importances_ for tree in rfc.estimators_], axis=0)
# Ensure xtrain is a DataFrame with column names
if not isinstance(xtrain, pd.DataFrame):
xtrain = pd.DataFrame(xtrain)
xtrain.columns = [f"feature_{i}" for i in range(xtrain.shape[1])]
print("Feature ranking:")
for f in range(min(20, xtrain.shape[1])):
print(f"{f + 1:2d}){xtrain.columns[indices[f]].ljust(30)}{importances[indices[f]]:.4f}")
plt.figure()
plt.title("Feature importances")
plt.bar(range(xtrain.shape[1]), importances[indices], color='r', yerr=std[indices], align="center")
plt.xticks(range(xtrain.shape[1]), xtrain.columns[indices], rotation=90)
plt.xlim([-1, xtrain.shape[1]])
plt.show()
这段代码首先检查xtrain是否是DataFrame类型,如果不是,则将其转换为DataFrame并添加默认列名。然后,它打印特征排名,并绘制特征重要性图,其中x轴的标签是特征名称。
按照上述步骤操作后,你应该能够解决'numpy.ndarray' object has no attribute 'columns'的错误,并成功绘制出特征重要性的图表。
分享 创建了问题
6月14日
创建了问题
6月14日

