


 分享
分享
以下内容由CHATGPT及阿里嘎多学长共同生成、有用望采纳:
根据您提供的信息,您在使用Python和Scrapy框架来爬取豆瓣电影Top 250的数据,但是遇到了问题,爬虫运行后无法得到预期的结果。我将根据您提供的几个文件内容来分析可能的问题所在。
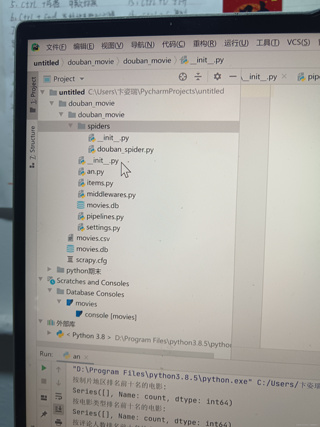
首先,我会检查douban_spider.py文件中的爬虫逻辑是否正确。从您提供的文件内容来看,这个文件应该包含了爬取豆瓣电影数据的逻辑。需要确保的是,爬虫能够正确地访问豆瓣电影Top 250的页面,并且能够解析出所需的数据。
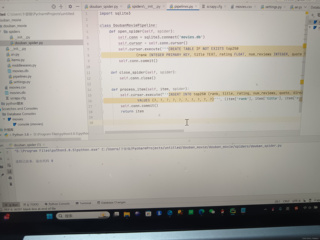
接着,我会查看pipelines.py文件,这个文件负责处理爬虫抓取的数据,并将数据存储到数据库中。从您提供的代码片段来看,DoubanMoviePipeline类负责打开数据库连接、创建表、插入数据和关闭数据库连接。需要检查的是,数据库表的创建语句是否正确,以及数据插入语句是否正确执行。
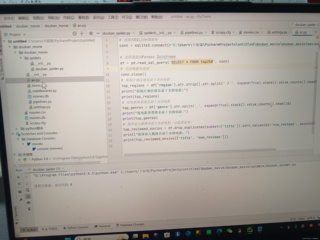
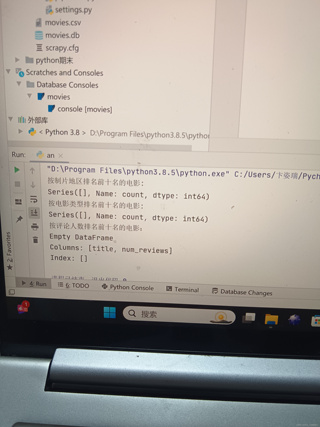
然后,我会检查an.py文件,这个文件看起来是用于数据库操作的Python脚本。这里需要确保数据库连接字符串是正确的,并且查询语句能够正确执行。
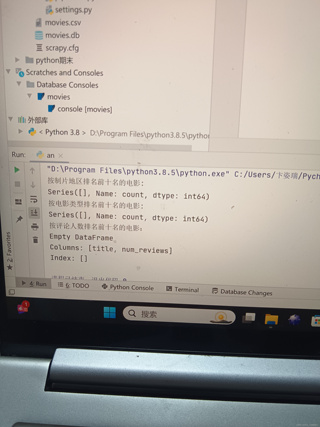
最后,我会查看movies.db数据库文件和movies.csv数据文件,以确保数据被正确存储和导出。
从您提供的终端和数据库控制台输出来看,似乎在尝试获取按评论人数排名前十名的电影时出现了问题,返回了一个空的DataFrame。这可能是因为爬虫没有正确地抓取到评论人数的数据,或者是在数据处理时出现了问题。
解决方案:
检查爬虫逻辑:确保douban_spider.py中的选择器(selectors)能够正确匹配到豆瓣电影Top 250页面上的数据。
检查数据库操作:在pipelines.py中,检查CREATE TABLE语句是否正确定义了所有需要的列,特别是num_reviews列。同时,检查INSERT INTO语句是否正确地使用了这些列。
检查数据处理:在an.py中,检查数据读取和处理的逻辑是否正确,特别是对num_reviews的处理。
检查输出:确保在终端和数据库控制台的输出中没有错误信息,如果有,根据错误信息进行调试。
测试和调试:在本地环境中运行爬虫,逐步调试每个部分,查看数据是否在每个步骤中都被正确处理。
由于我无法直接访问您提供的图片链接,以上建议是基于您提供的文本内容进行的分析。如果您能够提供具体的代码片段或错误信息,我可以提供更具体的帮助。同时,如果您需要进一步的帮助,可以上传相关文件,我可以为您提供更详细的分析和解决方案。
分享 创建了问题
6月21日
创建了问题
6月21日

