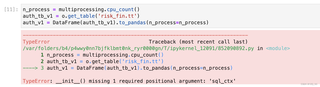
本地notebook通过odps访问线上数据库表时出现报错:
执行代码:
n_process = multiprocessing.cpu_count()
auth_tb_v1 = o.get_table('risk_fin.tt')
auth_v1 = DataFrame(auth_tb_v1).to_pandas(n_process=n_process)
报错内容:
---------------------------------------------------------------------------
TypeError Traceback (most recent call last)
/var/folders/b4/p4wwy0nn7bjfklbmt0nk_ryr0000gn/T/ipykernel_12091/852090892.py in <module>
1 n_process = multiprocessing.cpu_count()
2 auth_tb_v1 = o.get_table('risk_fin.tt')
----> 3 auth_v1 = DataFrame(auth_tb_v1).to_pandas(n_process=n_process)
TypeError: __init__() missing 1 required positional argument: 'sql_ctx'