
python爬虫运行豆瓣网页,bs4有错误?
代码:
运行截图:
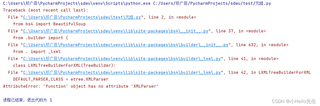

python爬虫运行豆瓣网页,bs4有错误?
代码:
 分享
分享
 关注
关注引自免费微信小程序:皆我百晓生
首先,对于你在使用BeautifulSoup解析豆瓣网页时遇到的问题,我会尝试帮助你解决。但是,我需要你提供更多的信息,比如具体的错误信息和代码片段,以便我能更准确地定位问题。关于你提供的图3和图4,看起来像是与LXML解析器有关的问题。
对于你遇到的错误“AttributeError: 'function' object has no attribute 'XMLParser'”,这个错误可能是因为你的环境中的LXML库有问题或者版本不兼容。以下是一些可能的解决方案:
pip uninstall lxml
pip install lxml
pip install lxml
然后,在你的代码中,你可以这样指定使用LXML作为解析器:
soup = BeautifulSoup(html, "lxml")
关于你的代码部分,我发现一处可能的错误。在你的代码中,你使用了变量名all_titles,但是在你的代码中并没有定义这个变量。你应该使用alttitles这个变量名来遍历和打印标题。以下是修正后的代码:
for title in alttitles:
title_string = title.string
if " / " not in title_string:
print(title_string)
希望这些解决方案能够帮助你解决问题。如果问题仍然存在,请提供更多的错误信息和代码片段,以便我能更准确地帮助你解决问题。
分享 系统已结题
8月2日
系统已结题
8月2日 已采纳回答
7月25日
创建了问题
7月25日
已采纳回答
7月25日
创建了问题
7月25日


