最近做的项目是古籍ocr识别,然后在我下载了古籍训练集后对图片用
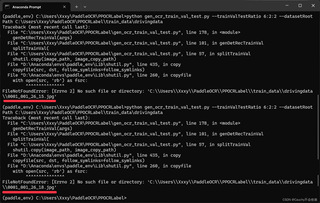
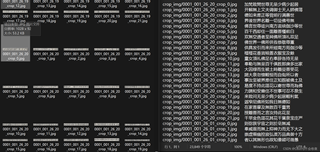
ppocrlabel进行处理,导出后在划分数据集就出现了图一这样的问题,一直报错不存在某张图片,而且每一次报错的图片都不一样。我也去找了确实没有那个名字的图片,但是crop_img与标签里的图片名字都是对的上的(如图二)。于是我换成其他数据集做试验,但并没有出现这种问题。实在不太懂怎么解决了。
还有在拿另一个数据集进行划分的时候,因为我在PaddleOCR文件夹下建立有train_data文件,在PaddleOCR 下的PPOCRLabel文件夹中也建立有train_data文件,(意思是有一个train_data文件与PPOCRLabel平行存在于PaddleOCR 下),我拿PPOCRLabel下的train_data文件进行划分后划分后的det与rec放到了 PaddleOCR下的train_data里,但是因为要进入cd PPOCRLabel才能进行数据集的划分,所以我用放在PaddleOCR下的train_data文件里的数据划分是不行的。我进入到PPOCRLabel下的gen_ocr_train_val_test.py 下直接更改default的路径进行运行也没法进行划分,都是说找不到文件。