
为什么logstash解析到的数据,message是个数组,message重复
logstash.conf配置如下:
input {
beats {
port => 5044
}
file{
path => ["/var/log/logstash/info.log"]
start_position => "beginning"
sincedb_path => "/dev/null"
}
}
filter{
grok{
match => { "message" => "%{TIMESTAMP_ISO8601:timestamp} %{LOGLEVEL:loglevel} %{NUMBER:pid} --- \[%{DATA:thread}\] %{JAVACLASS:package} : %{GREEDYDATA:message}"}
}
}
output {
elasticsearch {
hosts => ["http://172.17.0.2:9200"]
index => "elk"
codec => "json"
}
stdout {
codec => rubydebug
}
}
这是info.log日志文件

这logstash解析的日志
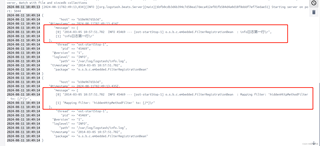
请问哪里有问题,为什么message是数组。






