怎么解决 flink通过HoodiePipeline 写数据到hudi表 产生大量的日志
是用的flink的yarn-session启的容器 里面只有这一个任务
写入代码
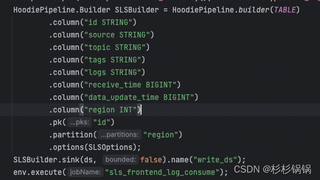
日志截图
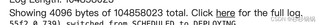
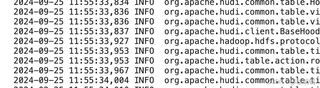
看日志感觉是写hudi时间产生的
设置了日志配置
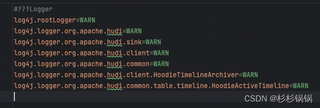

但是没有生效

请求解答

怎么解决 flink通过HoodiePipeline 写数据到hudi表 产生大量的日志
是用的flink的yarn-session启的容器 里面只有这一个任务
写入代码
日志截图
看日志感觉是写hudi时间产生的
设置了日志配置
但是没有生效
请求解答
 分享
分享
以下回复参考:皆我百晓生、券券喵儿等免费微信小程序作答:
要解决在Flink中通过Hoodie Pipeline写数据到Hoodie表并产生大量日志的问题,可以采用以下策略:
首先确保日志级别设置正确。对于Flink和Hoodie的日志记录,可以通过修改log4j.properties文件中的rootLogger和logger部分来控制日志输出。
log4j.rootLogger=WARN
log4j.logger.org.apache.hudi=WARN
这将使所有的Flink操作都默认为WARN级别,并且只对Apache Hudi进行警告级别的记录。
确保日志格式与输出的日志文件类型匹配。例如,如果你正在使用HoodieTimelineArchiver来存储活动日志,那么可能需要调整log4j.properties以指定正确的日志文件格式。
确保日志被正确地写入到文件系统中。这里主要考虑的是如何有效地管理大文件,特别是当文件大小超过一定阈值时。
// 在StreamExecutionEnvironment中添加日志收集器
env.addSource(new LogCollector());
为了防止过大的日志文件导致磁盘空间不足,可以考虑日志轮换和定期删除旧日志文件。
// 每隔一段时间(如每小时)检查旧的日志文件并移除它们
ScheduledExecutorService executorService = Executors.newSingleThreadScheduledExecutor();
executorService.scheduleAtFixedRate(() -> {
File oldLogFile = new File("/path/to/logfile.log");
if (oldLogFile.exists()) {
// 删除旧的日志文件
oldLogFile.delete();
}
}, 0, 1, TimeUnit.HOURS);
确保有足够的RAM和CPU资源来处理大文件以及执行所有必要的操作。
// 设置适当的内存限制
env.setMemoryLimit("1G");
在写入大量数据之前,应先尝试性写入少量数据来验证数据写入是否正常。
在整个过程中,务必包括数据校验和错误处理机制,以确保数据安全性和完整性。
// 加载数据前进行校验
DataStream<String> dataToLoad = env.fromCollection(Arrays.asList("Hello", "World"));
// ...
通过以上步骤,应该能够有效解决通过Hoodie Pipeline写数据到Hoodie表并产生大量日志的问题。
分享 创建了问题
9月26日
创建了问题
9月26日

