描述
著名的考古学家石教授在云梦高原上发现了一处古代城市遗址。让教授欣喜的是在这个他称为冰峰城 (Ice-Peak City) 的城市中有 12 块巨大石碑,上面刻着用某种文字书写的资料,他称这种文字为冰峰文。然而当教授试图再次找到冰峰城时,却屡屡无功而返。
幸好当时教授把石碑上的文字都拍摄了下来,为了解开冰峰城的秘密,教授和他的助手牛博士开始研究冰峰文,发现冰峰文只有陈述句这一种句型和名词 (n) 、动词 (v) 、辅词 (a) 这三类单词,且其文法很简单:
<文章> ::= <句子> { <句子> }
<句子> ::= <陈述句>
<陈述句> ::= <名词短语> { <动词短语> <名词短语> } [ <动词短语> ]
<名词短语> ::= <名词> | [ <辅词> ] <名词短语>
<动词短语> ::= <动词> | [ <辅词> ] <动词短语>
<单词> ::= <名词> | <动词> | <辅词>
注:其中<名词>、<动词>和<辅词>由词典给出,“::=”表示定义为,“|”表示或,{}内的项可以重复任意多次或不出现,[]内的项可以出现一次或不出现。
在研究了大量资料后,他们总结了一部冰峰文词典,由于冰峰文恰好有 26 个字母,为了研究方便,用字母 a 到 z 表示它们。
冰峰文在句子和句子之间以及单词和单词之间没有任何分隔符,因此划分单词和句子令石教授和牛博士感到非常麻烦,于是他们想到了使用计算机来帮助解决这个问题。假设你接受了这份工作,你的第一个任务是写一个程序,将一篇冰峰文文章划分为最少的句子,在这个前提下,将文章划分为最少的单词。
输入描述
第 1 行为词典中的单词数 n (n≤1000)。
第 2 行至第 (n+1) 行每行表示一个单词,形为 "α.mot" ,α 表示词性,可能是 n (名词), v(动词), a(辅词)中的一个, mot 为单词,单词的长度不超过 20 。拼写相同而词性不同的单词视为不同的单词,如输入示例中的 n.kick 与 v.kick 是两个不同的单词。
输入文件第 (n+2) 行为需要划分的文章,以 “.” 结束。
输入文件中的文章确保为冰峰文。文章是由有限个句子组成的,每个句子只包含有限个单词。文章长度不超过 5KB。
输出描述
为两行,每行一个整数。
第 1 行为划分出来的句子数。
第 2 行为划分出来的单词数。
样例输入 1
11
n.table
n.baleine
a.silly
n.snoopy
n.sillysnoopy
v.is
v.isnot
n.kick
v.kick
a.big
v.cry
sillysnoopyisnotbigtablebaleinekicksnoopysillycry.
样例输出 1
2
9
样例说明
(为了阅读方便,划分的单词用空格分隔,在单词的右上角标出它的词性,每行写一个句子,用句号表示句子结束。)
输出对应的划分:
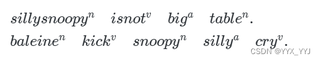
如果用下面的划分:
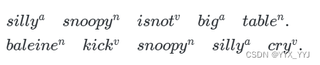
则划分的句子数仍为 2 个,但单词数却多了 1 个,为 10 个,显然应该按前者而不是后者划分。





