
为什么爬虫时使用.text/.get_text()无法进行标签内文本的提取,是代码有问题还是方法不对呢?希望好心的人可以指点一下,谢谢
这个是我的代码
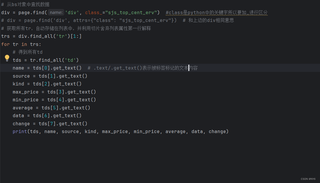
这个是我的运行结果

这个是我需要爬取的页面源码


为什么爬虫时使用.text/.get_text()无法进行标签内文本的提取,是代码有问题还是方法不对呢?希望好心的人可以指点一下,谢谢
这个是我的代码
这个是我的运行结果
这个是我需要爬取的页面源码
 分享
分享
以下回复参考:皆我百晓生、券券喵儿等免费微信小程序作答:
从你提供的代码和运行结果来看,问题可能出在获取文本内容的方式上。你使用的是 .get_text() 方法来获取标签内的文本内容,但在你的HTML结构中,产品名称、报价市场等文本信息实际上被包含在一个<a>标签内部,而这个<a>标签外面还有一个<td>标签。因此,直接使用 .get_text() 获取到的可能是包括<a>标签内的完整文本,包括链接和可能存在的其他格式化的文本。
为了正确获取你想要的数据,你应该首先定位到包含所需数据的<td>标签,然后再从该标签中获取文本内容。你可以使用 .text 或 .get_text() 方法来获取。这里是一个修改后的代码示例:
from bs4 import BeautifulSoup
# 假设你已经有了page这个BeautifulSoup对象
div = page.find("div", class_="sjs_top_cent_erv") # 注意这里修正了class属性的引用方式
trs = div.find_all('tr')[1:] # 获取所有的tr标签,并去掉第一行(通常是表头)
for tr in trs:
tds = tr.find_all('td') # 获取当前行所有的td标签
name_td = tds[0] # 产品名称所在的td标签
source_td = tds[1] # 报价市场所在的td标签
kind_td = tds[2] # 规格所在的td标签
max_price_td = tds[3] # 最高价所在的td标签
min_price_td = tds[4] # 最低价所在的td标签
average_td = tds[5] # 平均价所在的td标签
data_td = tds[6] # 报价日期所在的td标签
change_td = tds[7] # 走势图所在的td标签(这里可能需要特殊处理,因为它包含了图片和链接)
name = name_td.get_text() # 获取产品名称的文本内容
source = source_td.get_text() # 获取报价市场的文本内容
kind = kind_td.get_text() # 获取规格的文本内容
max_price = max_price_td.get_text().strip() # 获取最高价的文本内容,可能需要去除多余的空格或格式符
min_price = min_price_td.get_text().strip() # 同上处理最低价
average = average_td.get_text().strip() # 同上处理平均价
data = data_td.get_text().strip() # 获取报价日期的文本内容,并去除可能的格式符或额外内容(如果需要处理图片和链接,可能需要进一步解析)
print(name, source, kind, max_price, min_price, average, data) # 打印获取到的数据
注意:在解析包含复杂HTML结构的数据时,可能需要更精细地处理不同的情况,比如处理链接、图片或其他元素。上面的代码是一个基本的示例,可能需要根据你的实际HTML结构和需求进行调整。
分享 系统已结题
11月2日
系统已结题
11月2日 已采纳回答
10月25日
创建了问题
10月18日
已采纳回答
10月25日
创建了问题
10月18日

