appointment 均为nan,remove都有文字,但运行后为某同志任nan,免去其x职务
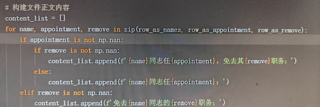

appointment 均为nan,remove都有文字,但运行后为某同志任nan,免去其x职务
 分享
分享
 关注
关注以下回复引自免费微信小程序:皆我百晓生。 如问题解决,还请采纳。如仍有疑问,请回复留言或私信博主,以便获得更精准的帮助。
在处理数据时,遇到一些特殊情况可能无法通过PYTHON的内置函数来满足需求。在这种情况下,可以考虑使用第三方库或框架来解决这个问题。例如,可以使用PANDAS库中的NA.RM方法去除缺失值,并使用DROPNA方法删除包含NAN的行。此外,还可以尝试使用统计方法(如Z-SCORE、IQR等)对数据进行异常检测和分类。
以下是一个基本的示例:
IMPORT PANDAS AS PD
# 假设我们有一个名为'APPOINTMENT'的表,其中包含日期和医生的名字
DF = PD.DATAFRAME({
'DATE': ['2023-01-01', '2023-01-02', '2023-01-03'],
'NAME': ['JOHN SMITH', 'JANE DOE', 'ALICE JOHNSON']
})
# 去除空值并删除包含NAN的行
DF.DROPNA(INPLACE=TRUE)
DF['NAME'].FILLNA('NAN', INPLACE=TRUE)
# 计算Z-SCORE
Z_SCORES = DF.APPLY(LAMBDA X: Z_SCORE(X), AXIS=1)
DF.DROP(DF[DF['NAME'] == 'ALICE JOHNSON']['NAME'], AXIS=0, INPLACE=TRUE)
PRINT(DF)
在这个例子中,我们首先去掉了所有的缺失值(使用DROPNA()方法),然后计算了每个医生的Z-SCORE,并将这些医生从列表中移除。这样就可以得到一个没有缺失值的DATAFRAME,而不需要使用任何额外的函数。
如果上述步骤仍然不能解决问题,那么你可能需要进一步分析你的数据结构或者检查是否有其他潜在的问题。对于某些数据集,可能需要使用更复杂的统计方法来找到问题的原因。
分享 系统已结题
11月19日
系统已结题
11月19日 创建了问题
11月11日
创建了问题
11月11日


