
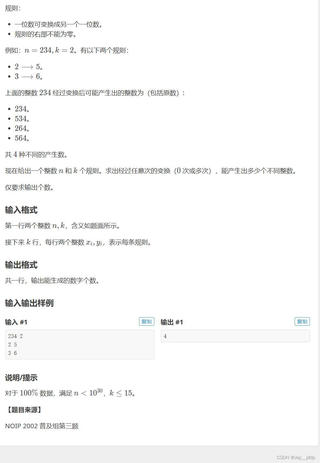
洛谷上的题目:
这是我的代码,应该是当n很大时,超时以及超内存了,要怎么修改我的代码啊,用的是python
def dfs(rule,n,total_number):
if n in total_number:
return
total_number.add(n)
for i in range(len(n)):
flag = int(n[i])
if flag in rule:
new_flag = rule[flag]
new_n = n[:i] + str(new_flag) + n[i+1:]
dfs(rule,new_n,total_number)
def count_number(rule,n,k):
n = str(n)
total_number = set() #存储可能产生的数(不重复)
dfs(rule,n,total_number)
return len(total_number)
if __name__ == '__main__':
n,k = map(int,input().split())
rule = {}
for i in range(k):
x,y = map(int,input().split())
rule[x] = y
print(count_number(rule,n,k))






