老shi们,请问我在做Yolov5影像辨识,划定警戒区域代码报错,请问要怎么解决,怎么改代码
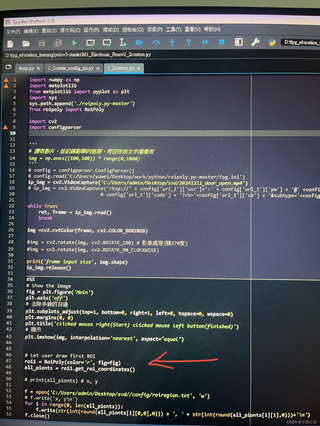
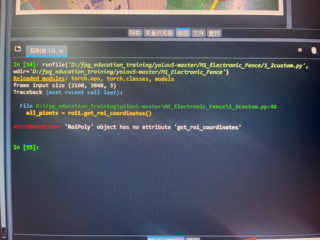

老shi们,请问我在做Yolov5影像辨识,划定警戒区域代码报错,请问要怎么解决,怎么改代码
 分享
分享
 关注
关注让【道友老李】来帮你解答,本回答参考通义千问大模型编写,并整理提供,如果还有疑问可以点击头像关注私信或评论。
如果答案让您满意,请采纳、关注,非常感谢!您好!根据您提供的信息,您正在使用YOLOv5进行影像辨识,并尝试在视频或图像中划定警戒区域时遇到了代码错误。由于没有直接看到您的代码文本,我将基于常见的问题和解决方案来给出一些建议。如果可以的话,请分享具体的错误消息或者更详细的代码片段,这样可以帮助更准确地定位问题。
从您分享的图片来看,似乎是在处理视频流(或一系列帧)的过程中试图绘制特定区域并检测该区域内是否有目标物体进入。这类任务通常涉及到以下步骤: 1. 读取视频帧。 2. 对每一帧执行对象检测。 3. 定义警戒区。 4. 检查检测到的对象是否位于警戒区内。 5. 根据结果采取行动(如标记、报警等)。
torch, opencv-python, 和 numpy。下面是一个简化版的例子,展示如何设置警戒区域并在检测到物体进入此区域时进行标注。请根据实际情况调整坐标和其他参数。
import cv2
import torch
from pathlib import Path
import numpy as np
# 加载模型
model = torch.hub.load('ultralytics/yolov5', 'yolov5s') # 或者加载本地训练好的模型
# 视频路径
video_path = "your_video.mp4"
cap = cv2.VideoCapture(video_path)
# 警戒区域 (x, y, w, h)
alert_zone = (100, 100, 300, 200) # 示例坐标,需要根据实际需求修改
while cap.isOpened():
ret, frame = cap.read()
if not ret:
break
# 执行推理
results = model(frame)
# 获取预测结果
df = results.pandas().xyxy[0]
# 绘制警戒区
x, y, w, h = alert_zone
cv2.rectangle(frame, (x, y), (x + w, y + h), (0, 255, 0), 2)
for index, row in df.iterrows():
xmin, ymin, xmax, ymax, confidence, class_name, name = int(row['xmin']), int(row['ymin']), int(row['xmax']), int(row['ymax']), float(row['confidence']), int(row['class']), row['name']
# 判断物体中心点是否在警戒区内
obj_center_x, obj_center_y = (xmin + xmax) // 2, (ymin + ymax) // 2
if x < obj_center_x < x + w and y < obj_center_y < y + h:
print(f"警告: {name} 进入了警戒区")
cv2.rectangle(frame, (xmin, ymin), (xmax, ymax), (0, 0, 255), 2)
cv2.putText(frame, f"{name} in Alert Zone", (xmin, ymin - 10), cv2.FONT_HERSHEY_SIMPLEX, 0.9, (0, 0, 255), 2)
else:
cv2.rectangle(frame, (xmin, ymin), (xmax, ymax), (255, 0, 0), 2)
cv2.imshow("Frame", frame)
if cv2.waitKey(1) & 0xFF == ord('q'):
break
cap.release()
cv2.destroyAllWindows()
这段代码首先加载了YOLOv5模型,然后对输入视频中的每一帧进行处理。它会画出一个矩形表示警戒区域,并检查每个被识别的对象是否进入了这个区域。如果是,则会在屏幕上标示出来。
希望这能帮助到您解决问题!如果有更多具体的问题或者遇到其他错误,请随时提供更多信息。
分享 创建了问题
12月30日
创建了问题
12月30日


