
请问下,使用TimeGPT预测时序数据的效果很差是怎么回事?
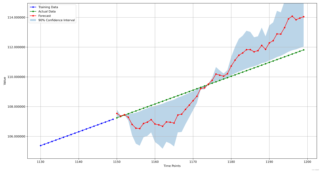
原始数据有1150个数据点,几乎是一条直线,根据这些数据预测后面50个点,但是预测出来的数据偏差很大
这是我的原始代码
import pandas as pd
import numpy as np
from nixtla import NixtlaClient
from utilsforecast.losses import mae, smape
from utilsforecast.evaluation import evaluate
import matplotlib.pyplot as plt
# 读取xlsx文件
df = pd.read_excel('TimeGPT/2.xlsx')
# 获取所有列名
columns = df.columns.tolist()
time_col = columns[1] # 第二列是时间
# 准备数据
train_size = 1150
train_df = pd.DataFrame({
'unique_id': 'id1',
'ds': df[time_col][:train_size],
'y': df['y'][:train_size] # 使用y列数据
})
# 准备测试数据
test_df = pd.DataFrame({
'unique_id': 'id1',
'ds': df[time_col][train_size:train_size+50],
'y': df['y'][train_size:train_size+50]
})
# 初始化 NixtlaClient
client = NixtlaClient(api_key='apikey')
# 预测(使用长期预测模式)
fcst = client.forecast(
df=train_df,
h=50, # 预测未来50个点
freq='s', # 频率为秒
level=[90], # 添加90%置信区间
time_col='ds',
target_col='y',
finetune_steps=20,
model='timegpt-1-long-horizon' # 使用长期预测模式
)
# 确保时间列是datetime类型
fcst['ds'] = pd.to_datetime(fcst['ds'])
test_df['ds'] = pd.to_datetime(test_df['ds'])
# 合并测试数据和预测结果
merged_df = pd.merge(test_df, fcst, 'left', ['unique_id', 'ds'])
# 评估预测性能
evaluation = evaluate(
merged_df,
metrics=[mae, smape],
models=["TimeGPT"],
target_col="y",
id_col='unique_id'
)
# 打印评估结果
average_metrics = evaluation.groupby('metric')['TimeGPT'].mean()
print("\n预测评估结果:")
print(f"MAE (平均绝对误差): {average_metrics['mae']:.6f}")
print(f"SMAPE (对称平均绝对百分比误差): {average_metrics['smape']:.6f}%")
# 打印一些实际值和预测值的对比
print("\n实际值vs预测值对比(前5个点):")
comparison_df = pd.DataFrame({
'Time': merged_df['ds'],
'Actual': merged_df['y'],
'Predicted': merged_df['TimeGPT']
})
print(comparison_df.head())
# 打印预测结果的列名
print("\n预测结果的列名:", fcst.columns.tolist())
# 计算时间秒数(用于绘图)
base_time = df[time_col].iloc[0] # 使用第一个时间点作为基准
all_seconds = range(len(df)) # 使用简单的序号作为x轴
forecast_seconds = range(train_size, train_size + len(fcst)) # 预测点的序号
# 创建图表
plt.figure(figsize=(15, 8))
# 绘制预测区域
display_start = train_size - 20
plt.plot(range(display_start, train_size),
df['y'][display_start:train_size],
'o-', label='Training Data', color='blue', markersize=4)
plt.plot(range(train_size, train_size+50),
df['y'][train_size:train_size+50],
'o-', label='Actual Data', color='green', markersize=4)
plt.plot(forecast_seconds, fcst['TimeGPT'],
'o-', label='Forecast', color='red', markersize=4)
# 添加置信区间(如果存在)
if 'TimeGPT-lo-90' in fcst.columns:
plt.fill_between(
forecast_seconds,
fcst['TimeGPT-lo-90'],
fcst['TimeGPT-hi-90'],
alpha=0.3,
label='90% Confidence Interval'
)
# 设置y轴范围,使用更精确的范围
display_data = pd.concat([
df['y'][display_start:train_size+50],
fcst['TimeGPT']
])
y_min = display_data.min()
y_max = display_data.max()
margin = (y_max - y_min) * 0.1 # 10%的边距
plt.ylim(y_min - margin, y_max + margin)
# 设置y轴刻度格式
plt.gca().yaxis.set_major_formatter(plt.FormatStrFormatter('%.6f'))
# 调整图表布局
plt.xlabel('Time Points')
plt.ylabel('Value')
plt.legend()
plt.grid(True)
plt.tight_layout()
# 保存高DPI的图片
plt.savefig('TimeGPT/forecast_2.png', dpi=300)
plt.close()
# 打印数值对比
print("\n数值对比详情:")
comparison_df['Difference'] = comparison_df['Actual'] - comparison_df['Predicted']
pd.set_option('display.float_format', lambda x: '%.8f' % x)
print(comparison_df)
# 保存预测结果
fcst.to_csv('TimeGPT/forecast_2.csv')
print("\n预测完成!图片和预测数据已保存到realData1目录下。")
这是预测结果(我只画出预测的那段时间附近
)





