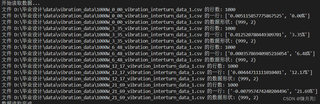
现在我遇到一个情况,就是在读取csv文件时,每个文件都是有1000行数据,但是读取后就是都会少一行数据,只有999个。想知道问一下各位,是代码出现了问题还是其他问题?下面是部分代码和运行后的结果。
# 读取每个CSV文件并提取特征和标签
for file in files:
try:
# 使用csv模块读取文件
with open(file, 'r', encoding='utf-8') as f:
reader = csv.reader(f)
rows = list(reader)
print(f"文件 {file} 的行数: {len(rows)}")
print(f"文件 {file} 的最后一行: {rows[-1]}")
# 使用pandas读取文件
data = pd.read_csv(file, encoding='utf-8', on_bad_lines='warn')
print(f"文件 {file} 的数据形状: {data.shape}") # 检查数据形状
features = data.iloc[:, :-1].values # 获取所有行的前n-1列作为特征
labels = data.iloc[:, -1].values # 获取所有行的最后一列作为标签
x.extend(features) # 添加特征到x列表
y.extend(labels) # 添加标签到y列表
except Exception as e:
print(f"读取文件 {file} 时出错: {e}")
print("数据读取完成。")