为什么stata生成新变量的时候显示无意义的名字r(198)
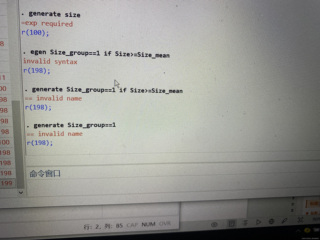

为什么stata生成新变量的时候显示无意义的名字r(198)
 分享
分享
 关注
关注让【道友老李】来帮你解答,本回答参考gpt编写,并整理提供,如果还有疑问可以点击头像关注私信或评论。
如果答案让您满意,请采纳、关注,非常感谢!在 Stata 中生成新变量时,如果出现无意义的名称,如“r(198)”,通常是因为 Stata 对生成变量的命名规则存在一定限制,具体原因通常包括以下几种情况:
当你尝试生成一个已经存在的变量时,Stata 会返回错误代码 r(198),表示变量已存在。如果你写的代码试图创建一个新变量,但这个名称已经被用于另一个变量,Stata 不会再允许你重复使用这个变量的名称。 案例:
// 假设已经存在一个名为 age 的变量
gen age = 25 // 生成变量 age
// 再次尝试生成同名变量
gen age = 30 // 这条命令将会导致 r(198)
如果你生成变量时使用了不符合 Stata 允许的变量命名规则,如使用了空格或特殊字符等,Stata 会返回相应的错误。 代码示例:
// 尝试生成一个包含空格的变量名
gen "new variable" = 1 // 会导致错误
为了避免遇到 r(198) 错误,可以采取以下措施: 1. 检查变量名是否已经存在: 在生成变量之前,可以使用命令 describe 查看当前数据集中已有变量的列表。
describe
age_new。下面是一个完整的示例,阐明了如何安全地生成新变量:
// 创建一个示例数据集
clear
set obs 5
gen id = _n
gen age = 25
// 尝试生成一个新的变量来存储年龄加5
// 由于 `age` 已经存在,使用一个不同的名称
gen age_plus5 = age + 5
// 检查数据集
list
变量命名时要确保唯一性和合法性,这样才能避免在 Stata 中生成新变量时遇到无意义的名称 r(198) 错误。通过有效管理变量名,可以提高数据分析的效率和准确性。
分享 系统已结题
11月6日
系统已结题
11月6日 已采纳回答
10月29日
创建了问题
2月9日
已采纳回答
10月29日
创建了问题
2月9日


