
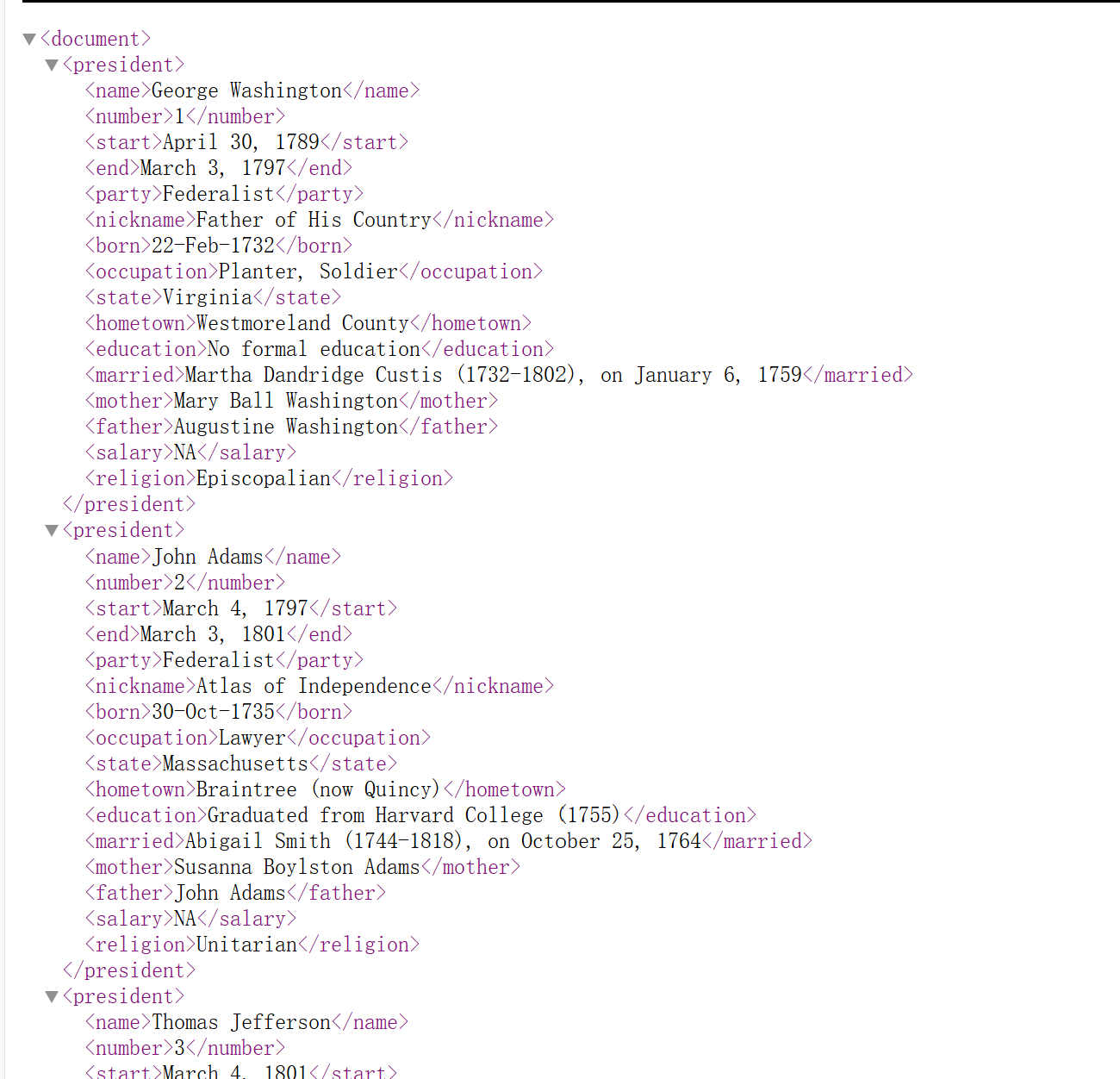
XML文件potus.xml包含了美国总统的传记信息。解析文件,并通过Xpath语句提取以下信息:
(1)提取所有总统的姓名;
(2)从第40任总统开始,提取总统的姓名;
(3)提取所有party标签是共和党(Republican)总统的职业(occupation)
求解答

(1)提取所有总统的姓名;
(2)从第40任总统开始,提取总统的姓名;
(3)提取所有party标签是共和党(Republican)总统的职业(occupation)
求解答
 分享
分享
阿里嘎多学长整理AIGC生成,因移动端显示问题导致当前答案未能完全显示,请使用PC端查看更加详细的解答过程
Python爬虫可以使用xml.etree.ElementTree模块来解析XML文件,下面是一个示例代码:
import xml.etree.ElementTree as ET
# 读取XML文件
tree = ET.parse('potus.xml')
root = tree.getroot()
# 提取所有总统的姓名
names = [president.find('name').text for president in root.findall('.//president')]
print(names)
# 提取从第40任总统开始的总统姓名
for president in root.findall('.//president')[39:]:
print(president.find('name').text)
# 提取所有party标签
parties = [president.find('party').text for president in root.findall('.//president')]
print(parties)
ET.parse函数读取XML文件,获取根元素。findall函数找到所有president元素。root.findall('.//president'):找到所有president元素,使用.表示当前元素,//表示从当前元素开始向下搜索。president.find('name').text:找到president元素下的name元素,并获取其文本内容。root.findall('.//president')[39:]:找到从第40任总统开始的总统元素,使用切片操作。president.find('party').text:找到president元素下的party元素,并获取其文本内容。 分享 系统已结题
4月20日
系统已结题
4月20日 已采纳回答
4月12日
创建了问题
4月9日
已采纳回答
4月12日
创建了问题
4月9日


