各位专家们,我在用stata做psm,匹配后的结果如图,在匹配的过程中遇到如下问题:
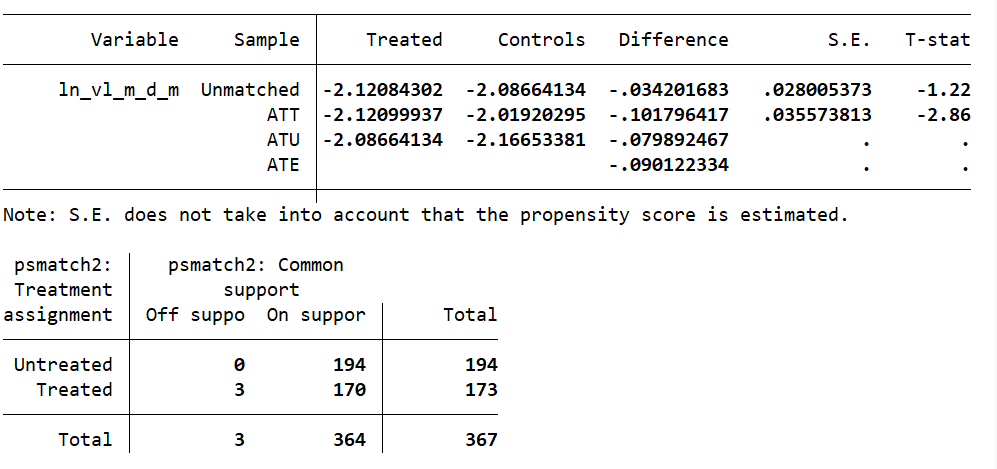
总共367个样本,off support的样本为3个,但是_weight为.的样本有96个。
请问后续做分析是直接drop off support,还是需要drop _weight为.呢?急救。


各位专家们,我在用stata做psm,匹配后的结果如图,在匹配的过程中遇到如下问题:
总共367个样本,off support的样本为3个,但是_weight为.的样本有96个。
请问后续做分析是直接drop off support,还是需要drop _weight为.呢?急救。
 分享
分享
 关注
关注让 “紫雾凌寒” 来帮你回答,本回答结合 DeepSeek
如果还有问题,请评论或点击头像私信,如果有帮助到您, 请关注、采纳、点赞
drop if _weight==.命令来剔除。但这种方法要谨慎使用,因为样本量减少可能会影响统计功效。covariate1的值是否合理:list covariate1 if _weight==.drop if _weight==.covariate1 covariate2stata
psmatch2 treat covariate1 covariate2, nnm希望以上解答对您有所帮助。如果您有任何疑问,欢迎在评论区提出。
分享 创建了问题
4月12日
创建了问题
4月12日

